GitOps using SystemD
Saturday 24 February 2024 · 56 mins read · Viewed 804 timesTable of contents 🔗
- Table of contents
- Introduction
- The recipe for pull-based GitOps
- Understanding the init system and service management
- Implementing the script
- Configuring the SystemD service
- Building the OS image
- Testing
- (Optional) Make the node reboot
- (Optional) Fetch the status and logs
- (Optional) Using a webhook to trigger the service
- Conclusion and Discussion
- References
Introduction 🔗
Zero-trust infrastructure is the golden objective of any security-conscious organization. The fact that you let no one and nothing inside your infrastructure without proper verification is the ultimate goal.
Pull-based GitOps helps to achieve this by prioritizing automated infrastructure management over manual "push" commands by using Git as the source of truth. Permissions are handled at the Git level, and the infrastructure is automatically updated based on the changes in the Git repository. No need to access the infrastructure directly to make changes.
In this article, I will present how to set up a SystemD service (or with any other init system) to achieve pull-based GitOps on VMs without the need to use Ansible.
The recipe for pull-based GitOps 🔗
Let's take ArgoCD as an example. ArgoCD is a pull-based GitOps tool that automatically updates the applications deployed on Kubernetes based on the changes in the Git repository.
ArgoCD achieves this by:
- Watching the Git repository for changes using a polling strategy. (Or open a public endpoint for webhooks.)
- Pulling the changes from the Git repository and comparing the old manifests with the new one, called the
Refreshaction. - Applying the changes to the Kubernetes cluster, called the
Syncaction on ArgoCD.
These steps are quite easy to implement, and we will see that later. However, for the developer experience, we also need:
- A way to get feedback about the state and the logs of the deployment.
- For VM, a way to reboot remotely by Git.
To get feedback about the state and the logs of the deployment, we need, from the node, to push the information to a central location. We can use any webhooks for this, so let's simply use a Discord Webhook.
To reboot a VM, we must avoid creating a boot loop and compare "boot" states. Basically, simply create timestamps to schedule reboot(s).
Now, that we have the recipe, let's see how to implement it.
Understanding the init system and service management 🔗
Do you remember how a Linux system boots? It starts in this order:
-
The BIOS/UEFI. The BIOS/UEFI is the first thing that is started when the computer is powered on. It is responsible for initializing the hardware and starting the bootloader.
-
The bootloader which is often GRUB. Clusters tend to use iPXE or PXE for network booting. The bootloader loads the kernel and the initramfs. The configuration stored in
/bootoften look like this:1menuentry "Arch Linux" { 2 # Label of the disk to find the loader and inird. 3 volume "Arch Linux" 4 # Kernel 5 loader /boot/vmlinuz-linux 6 # Init RAM disk file 7 initrd /boot/initramfs-linux.img 8 # Linux boot cmd. `root` indicates to mount the following volume as the root file system. 9 options "root=UUID=5f96cafa-e0a7-4057-b18f-fa709db5b837 rw" 10} -
The initramfs and kernel stored in
/boot. The initramfs is a temporary file system that is loaded into memory and used to mount the root file system. The kernel is the core of the operating system and is responsible for managing the hardware and starting the init system. -
The init system. The init system is the first process that is started by the kernel and is responsible for starting all other processes. Most of the time, the first executable is
/sbin/initor/usr/lib/systemd/systemd. Since this is the first process, it has the process ID 1.
SystemD is quite complex and supports many features (so many that it is called "bloated", but let's ignore that). It is the default init system on most Linux distributions, including Ubuntu, Fedora, Red Hat, CentOS, and Debian. Some distributions, like Alpine Linux, use simpler and easy to explain init system OpenRC or Runit.
SystemD is able to handle services, sockets, timers, and targets ("boot stages"), which makes it a good candidate for our GitOps implementation:
- To watch the Git repository for changes, we can use a timer, which is a unit that activates and deactivates other units based on time.
- We use targets to make sure the VM is in a good state before applying the changes. We want to boot after the ready is fully ready, so after the
network-online.targetis reached. - We use services to supervisor the process and avoid zombie or duplicate processes.
Note that SystemD is able to handle a complex dependency graph. We will see later how to configure the service with its dependencies. For now, let's implement the boot script/program used to pull the changes from the Git repository, compare them and apply them.
Implementing the script 🔗
We will use a simple shell script to pull the changes from the Git repository, compare them, and apply them.
server-side script: /gitops.sh
1#!/bin/bash
2
3# REPO_URL must be set as an environment variable.
4
5# x: debug
6# e: exit on error
7# u: exit on undefined variable
8# o pipefail: exit on error in pipe
9set -eux -o pipefail
10
11REPO_URL=${REPO_URL:-'https://github.com/Darkness4/node-config.git'}
12OUTPUT_DIR=/gitops
13
14# Make nothing is world-readable.
15umask 077
16
17if [ ! -d "$OUTPUT_DIR" ]; then
18 git clone "$REPO_URL" "$OUTPUT_DIR"
19 cd "$OUTPUT_DIR"
20 ./run.sh # We assume the run.sh is the script to apply the changes.
21else
22 cd "$OUTPUT_DIR"
23
24 git fetch
25
26 # Compare changes
27 LOCAL=$(git rev-parse @)
28 REMOTE=$(git rev-parse '@{u}')
29 BASE=$(git merge-base @ '@{u}')
30
31 if [ $LOCAL = $REMOTE ]; then
32 echo "Up-to-date"
33 elif [ $LOCAL = $BASE ]; then # Local is not remote, but the commit is in the history of the remote.
34 echo "Need to pull"
35 git pull
36 ./run.sh
37 elif [ $REMOTE = $BASE ]; then # Local is not remote, but the commit is not in the history of the remote (but still mergeable).
38 echo "Need to push"
39 exit 1
40 else # The commit is not in the history of the remote and not mergeable.
41 echo "Diverged"
42 exit 1
43 fi
44fi
It is very possible that you need to use a private/deploy key to pull the configuration. You've got at least three solutions:
- At build time, inject the private key in the OS image. This is the least flexible solution and not very secure if you plan to share that OS image.
- At run time, prepare the private key in a volume and mount it in the VM. This is the most flexible solution, but needs a two-step setup.
- At run time, use the SSH Host Key to log in to the Git repository. This is the most secure solution, but you need to enter to the VM to fetch the public key of all the hosts. This also doesn't work for stateless VMs.
To summarize, you need to have a private key and secure it using Linux permissions (chmod 600). The third method is the safest because you can whitelist per-node. The second method is the most flexible since you manage only one key for all the nodes.
If you opt for any method, add the following line to the script:
1# ...
2
3REPO_URL=${REPO_URL:-'https://github.com/Darkness4/node-config.git'}
4OUTPUT_DIR=/gitops
5# Use /path/to/key for the first and second method.
6# Use /etc/ssh/ssh_host_ed25519_key for the third method. Export the public key /etc/ssh/ssh_host_ed25519_key.pub to the Git repository.
7export GIT_SSH_COMMAND='ssh -i </path/to/key> -o IdentitiesOnly=yes -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null'
8
9# ...
Remember to chmod 600 the key file.
To avoid configuring that script for each, I recommend injecting the script directly in the OS image (we'll see that later). If your nodes are stateful, you can push the script using Ansible, or simply with parallel SSH since we are trying to avoid using Ansible. If you use cloud-init, you can use the write_files directive to inject the script.
Let's create a simple post boot script inside a Git repository:
run.sh
1#!/bin/sh
2
3cat <<EOF >/etc/motd
4------------------------
5My super light OS.
6Hostname: $(hostname)
7------------------------
8EOF
Example: github.com/Darkness4/node-config.
That's should be enough, with this simple entry point, we will be able to update the node remotely without having to access it directly. We will create a script to reboot if necessary. Let's configure the SystemD service.
Configuring the SystemD service 🔗
Let's create the service:
server-side: /etc/systemd/system/gitops.service
1[Unit]
2Description=GitOps configuration management
3Wants=network-online.target
4After=network-online.target
5
6[Service]
7User=root
8ExecStart=/gitops.sh
9Type=simple
10
11[Install]
12WantedBy=multi-user.target
Either add the service to your OS image (we'll see that later), or use Ansible or parallel SSH to push the service to the nodes.
Now, let's create the timer:
server-side: /etc/systemd/system/gitops.timer
1[Unit]
2Description=Run GitOps every 5 minutes
3
4[Timer]
5OnBootSec=5min
6OnUnitActiveSec=5min
7Unit=gitops.service
8
9[Install]
10WantedBy=timers.target
If you are not using SystemD, replace the timer by a cron job:
1*/5 * * * * root rc-service gitops start # Or systemctl start gitops.service, anything that start the service.
Add the service to your OS image (we'll see that later), or use Ansible or parallel SSH to push the service to the nodes.
Now, let's enable and start the timer:
1# Enable the timer
2systemctl enable gitops.timer
3# Start on boot
4systemctl enable gitops.service
If you are building an OS image, it is very possible that you are not able to run systemctl, therefore, create the symlink manually:
1ln -s /etc/systemd/system/gitops.timer /etc/systemd/system/timers.target.wants/gitops.timer
2ln -s /etc/systemd/system/gitops.service /etc/systemd/system/multi-user.target.wants/gitops.service
Building the OS image 🔗
In one of my previous article, I described how to build an OS image from scratch using Docker and the gentoo/stage3 container. While this method allow the creation of OSes without any bloat, it is not the most user-friendly method. I also want to take account that most of the readers want to use specifically binary OSes to avoid compiling on the nodes
Technically, you can use the Gentoo Binary Host if you want to deploy your own binary software on Gentoo.
This will permit you to create you own custom OS and binary repository. Basically, a way to fully avoid supply chain attacks. Isn't that cool?
For this article, we will use Packer and Rocky Linux to build the OS image. Packer automates the creation of OS images by using a VM. It is a good tool to use when you want to create OS images for different cloud providers.
It is also possible to "chain" Packer and Terraform, but we won't do that in this article. Everything will be done locally:
-
Install Packer.
-
Create a directory for the Packer configuration:
1mkdir -p ubuntu-gitops 2cd ubuntu-gitops -
Let's configure the template. We'll use QEMU to build our image. You can use VirtualBox or VMware if you prefer.
ubuntu-gitops/template.pkr.hcl
1packer { 2 required_plugins { 3 qemu = { 4 source = "github.com/hashicorp/qemu" 5 version = "~> 1" 6 } 7 } 8} 9 10variable "boot_wait" { 11 type = string 12 default = "3s" 13} 14 15variable "disk_size" { 16 type = string 17 default = "50G" 18} 19 20variable "iso_checksum" { 21 type = string 22 default = "eb096f0518e310f722d5ebd4c69f0322df4fc152c6189f93c5c797dc25f3d2e1" 23} 24 25variable "iso_url" { 26 type = string 27 default = "https://download.rockylinux.org/pub/rocky/9/isos/x86_64/Rocky-9.3-x86_64-boot.iso" 28} 29 30variable "memsize" { 31 type = string 32 default = "2048" 33} 34 35variable "numvcpus" { 36 type = string 37 default = "4" 38} 39 40source "qemu" "compute" { 41 accelerator = "kvm" 42 boot_command = ["<up><tab><bs><bs><bs><bs><bs> inst.ks=http://{{ .HTTPIP }}:{{ .HTTPPort }}/ks.cfg inst.cmdline<enter><wait>"] 43 boot_wait = "${var.boot_wait}" 44 communicator = "none" 45 cpus = "${var.numvcpus}" 46 disk_size = "${var.disk_size}" 47 headless = true 48 http_directory = "http" 49 iso_checksum = "${var.iso_checksum}" 50 iso_url = "${var.iso_url}" 51 memory = "${var.memsize}" 52 cpu_model = "host" 53 qemuargs = [["-serial", "stdio"]] 54 shutdown_timeout = "3h" 55 vnc_bind_address = "0.0.0.0" 56} 57 58build { 59 sources = ["source.qemu.compute"] 60}If this is your first time using Packer, let me explain the configuration:
boot_waitis the time to wait for the boot to complete. More precisely, it is the time to wait for the UEFI boot to complete before sending the boot command to the bootloader.boot_commandis command and key presses to send after the boot. Since Rocky Linux uses GRUB, we ask GRUD to deletequiet(5 backspaces) and replace it with a custom one. We also ask GRUB to use a kickstart file to install the OS. The kickstart file is a file that contains the installation instructions for the OS. We will create it later.http_directoryis the directory to serve the kickstart file. We will create it later.
The rest of the configuration is self-explanatory. Packer uses VNC, so you could use Remmina to debug the installation.
Run the following command to install the
qemuplugin:1packer init .You should also install
qemuby the way. I'll let you Google for it.- Create the kickstart file inside the
httpdirectory (you have to create it):
ubuntu-gitops/http/ks.cfg
1url --url="https://dl.rockylinux.org/pub/rocky/9.3/BaseOS/x86_64/os/" 2# License agreement 3eula --agreed 4# Disable Initial Setup on first boot 5firstboot --disable 6# Poweroff after the install is finished 7poweroff 8# Firewall 9firewall --disable 10ignoredisk --only-use=vda 11# System language 12lang en_US.UTF-8 13# Keyboard layout 14keyboard us 15# Network information 16network --bootproto=dhcp --device=eth0 17# SELinux configuration 18selinux --disabled 19# System timezone 20timezone UTC --utc 21# System bootloader configuration 22bootloader --location=mbr --driveorder="vda" --timeout=1 23# Root password 24# WARNING: Change the root password or remove this line. You can set the SSH public keu in the %post section. 25rootpw --plaintext changeme 26# System services 27services --enabled="chronyd" 28 29repo --name="AppStream" --baseurl=https://dl.rockylinux.org/pub/rocky/9.3/AppStream/x86_64/os/ 30#repo --name="Extras" --baseurl=https://dl.rockylinux.org/pub/rocky/9.3/extras/x86_64/os/ 31#repo --name="CRB" --baseurl=https://dl.rockylinux.org/pub/rocky/9.3/CRB/x86_64/os/ 32#repo --name="epel" --baseurl=https://mirror.init7.net/fedora/epel/9/Everything/x86_64/ 33#repo --name="elrepo" --baseurl=http://elrepo.org/linux/elrepo/el9/x86_64/ 34 35# Clear the Master Boot Record 36zerombr 37# Remove partitions 38clearpart --all --initlabel 39# Automatically create partition 40part / --size=1 --grow --asprimary --fstype=xfs 41 42# Postinstall 43%post --erroronfail 44cat << 'EOF' > /gitops.sh 45#!/bin/bash 46 47# REPO_URL must be set as an environment variable. 48mkdir -m0700 /root/.ssh/ 49 50cat <<EOF >/root/.ssh/authorized_keys 51ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIDUnXMBGq6bV6H+c7P5QjDn1soeB6vkodi6OswcZsMwH marc 52EOF 53 54chmod 0600 /root/.ssh/authorized_keys 55 56# x: debug 57# e: exit on error 58# u: exit on undefined variable 59# o pipefail: exit on error in pipe 60set -eux -o pipefail 61 62# Make nothing is world-readable. 63umask 077 64 65REPO_URL=${REPO_URL:-'https://github.com/Darkness4/node-config.git'} 66OUTPUT_DIR=/gitops 67 68if [ ! -d "$OUTPUT_DIR" ]; then 69 git clone "$REPO_URL" "$OUTPUT_DIR" 70 cd "$OUTPUT_DIR" 71 ./run.sh # We assume the run.sh is the script to apply the changes. 72else 73 cd "$OUTPUT_DIR" 74 75 git fetch 76 77 # Compare changes 78 LOCAL=$(git rev-parse @) 79 REMOTE=$(git rev-parse '@{u}') 80 BASE=$(git merge-base @ '@{u}') 81 82 if [ $LOCAL = $REMOTE ]; then 83 echo "Up-to-date" 84 elif [ $LOCAL = $BASE ]; then # Local is not remote, but the commit is in the history of the remote. 85 echo "Need to pull" 86 git pull 87 ./run.sh 88 elif [ $REMOTE = $BASE ]; then # Local is not remote, but the commit is not in the history of the remote (but still mergeable). 89 echo "Need to push" 90 exit 1 91 else # The commit is not in the history of the remote and not mergeable. 92 echo "Diverged" 93 exit 1 94 fi 95fi 96EOF 97chmod +x /gitops.sh 98cat << 'EOF' > /etc/systemd/system/gitops.service 99[Unit] 100Description=GitOps configuration management 101Wants=network-online.target 102After=network-online.target 103 104[Service] 105User=root 106ExecStart=/gitops.sh 107Type=simple 108 109[Install] 110WantedBy=multi-user.target 111EOF 112ln -s /etc/systemd/system/gitops.service /etc/systemd/system/multi-user.target.wants/gitops.service 113 114cat << 'EOF' > /etc/systemd/system/gitops.timer 115[Unit] 116Description=Run GitOps every 5 minutes 117 118[Timer] 119OnBootSec=5min 120OnUnitActiveSec=5min 121Unit=gitops.service 122 123[Install] 124WantedBy=timers.target 125EOF 126ln -s /etc/systemd/system/gitops.timer /etc/systemd/system/timers.target.wants/gitops.timer 127%end 128 129%packages --excludedocs 130@minimal-environment 131git 132 133-plymouth 134# Remove Intel wireless firmware 135-i*-firmware 136%end 137- Run the following command to build the OS image:
1packer build .
Testing 🔗
Let's launch the OS image using QEMU. I'm going to use virt-manager:
- Import existing disk image. Forward.
- "Browse...". Select the OS image (
/path/to/output-compute/packer-compute). SelectRocky Linux 9 (rocky9). Forward. - Select your memory and CPUs. Forward.
- Create a disk. Forward.
- Name. Network: NAT. Finish.
Start the VM. And hey it works:
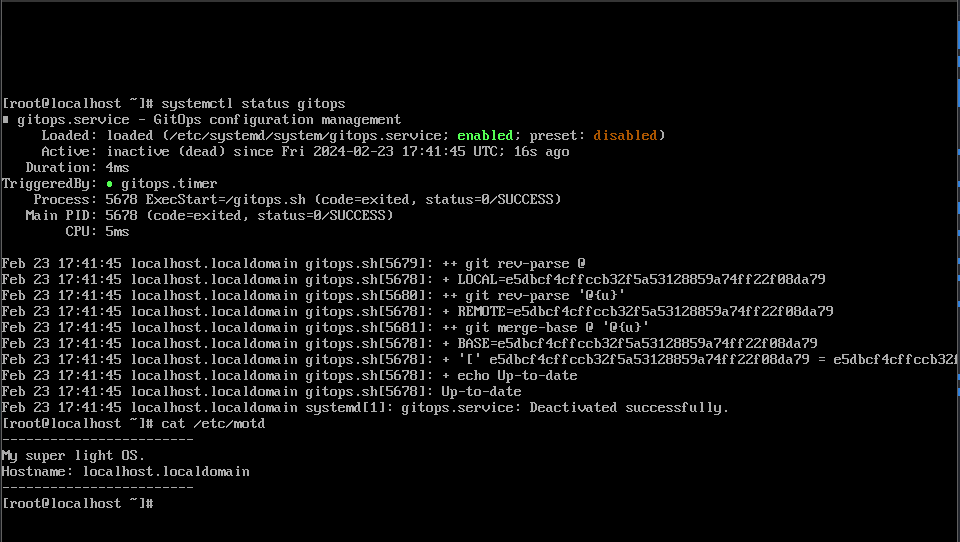
Let's change the postscript to:
1#!/bin/sh
2
3cat <<EOF >/etc/motd
4------------------------
5My super light OS. Easy to update.
6Hostname: $(hostname)
7------------------------
8EOF
And wait 5 minutes...:
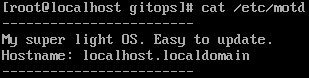
We've finally GitOps set up!
(Optional) Make the node reboot 🔗
The best way to make the node reboot and avoid a boot loop is by using the time. You can also use the fact that your node is stateful and create a file to indicate that the node has rebooted.
server-side: run.sh
1# ...
2
3schedule_reboot() {
4 # Format is "YYYY-MM-DD HH:MM:SS"
5 datetime=$1
6
7 # Convert input to epoch time
8 epoch_time=$(date -d "$datetime" +%s)
9
10 # Current epoch time
11 current_time=$(date +%s)
12
13 # Calculate time difference in seconds
14 time_diff=$((epoch_time - current_time))
15
16 # Check if the provided time is in the past
17 if [ $time_diff -le 0 ]; then
18 echo "Provided time is in the past. Please provide a future time."
19 return
20 fi
21
22 # Schedule reboot
23 echo "Reboot at: $datetime"
24 shutdown -r +$((time_diff / 60))
25}
26
27schedule_reboot "2024-02-23 19:05:00"
Commit & push.
If we wait and look at the journal or status journalctl status gitops.service:

(Optional) Fetch the status and logs 🔗
Basically, we need to fetch the logs and the return code of the script and push them to the Webhook:
-
In the Git repository, copy the
run.shscript topost.sh. -
Edit the
run.shscript and replace everything with:1#!/bin/sh 2 3chmod +x ./post.sh 4if ./post.sh | tee /var/log/gitops.log; then 5 curl -F "file1=@/var/log/gitops.log" -F 'payload_json={"content":"GitOps: Success"}' <webhook> 6else 7 curl -F "file1=@/var/log/gitops.log" -F 'payload_json={"content":"GitOps: Failure"}' <webhook> 8fi
Be aware that the webhook is a secret. Make your post scripts Git repository private. For the sake of the example, I will be using a request bin.
Result:
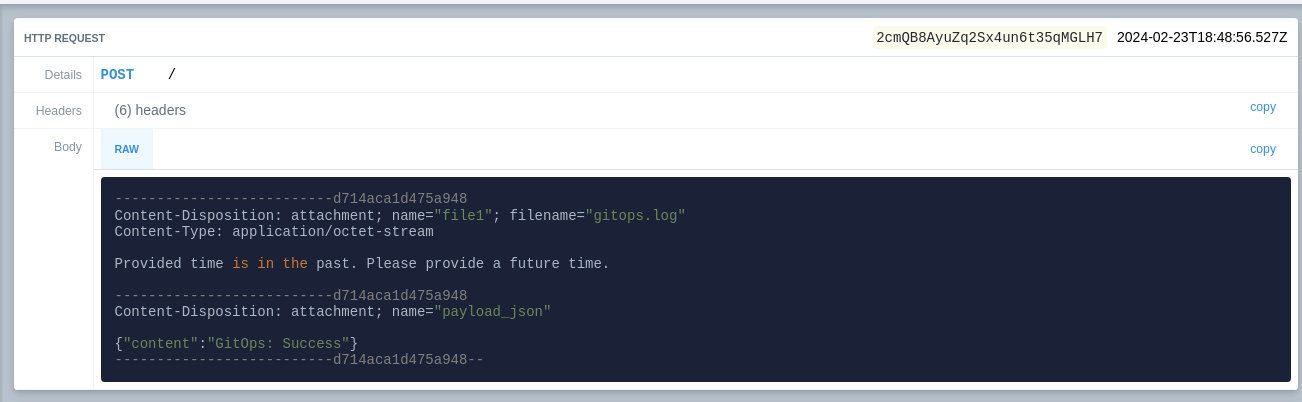
(Optional) Using a webhook to trigger the service 🔗
While this is contrary to "pull-based" GitOps, you sometime want to force the update of the node. You can use a webhook to trigger the service.
The objective is to create a simple HTTP server that listens for a POST request and triggers the service. The best way is to use a python script:
server-side: /gitops.py
1from http.server import BaseHTTPRequestHandler, HTTPServer
2import subprocess
3
4class RequestHandler(BaseHTTPRequestHandler):
5 def do_POST(self):
6 self.send_response(200)
7 self.end_headers()
8 # Trigger systemctl restart gitops.service
9 subprocess.run(['systemctl', 'restart', 'gitops.service'])
10
11def run(server_class=HTTPServer, handler_class=RequestHandler, port=8000):
12 server_address = ('', port)
13 httpd = server_class(server_address, handler_class)
14 print(f"Starting server on port {port}")
15 httpd.serve_forever()
16
17if __name__ == "__main__":
18 port = int(os.environ.get('PORT', 8000))
19 run(port=port)
This server will trigger systemctl restart gitops.service when a POST request is received.
You can install that script via run.sh or install it directly in the OS image. Just don't forget to run it as a service:
1[Unit]
2Description=GitOps Webhook
3After=network-online.target
4
5[Service]
6User=root
7ExecStart=/usr/bin/python3 /gitops.py
8Type=simple
9
10[Install]
11WantedBy=multi-user.target
Enable the service:
1systectl enable gitops-webhook
2# Or:
3ln -s /etc/systemd/system/gitops-webhook.service /etc/systemd/system/multi-user.target.wants/gitops-webhook.service
You will need to expose this server to the internet. Either use an NGINX or Traefik to route properly the request to the server.
Conclusion and Discussion 🔗
As you can see, with a pull-based GitOps, we avoid interacting with the infrastructure directly. We also don't need a management server to push the changes to the infrastructure. The only part that is quite "ugly" is the manner we are handling the private key to pull the configuration.
cloud-init suffer from the same disadvantage, but some cloud providers have a way to inject the private key in the VM using a disk.
Other cloud providers tries to obfuscate the HTTP server that serves the cloud-init configuration, but it is still possible to fetch the
configuration. The best method is still the third one: using the SSH Host Key to log in to the Git repository as they are generated.
This method could also work for Ansible by making a "GitOps" Ansible server where the timer executes the playbook.
Lastly, let's compare with other tools:
- Ansible and Puppet Bolt: Ansible and Puppet Bolt are push-based tools. Playbooks can be stored inside a Git repository, but the changes are pushed to the infrastructure using SSH. While it is close to GitOps, it doesn't allow a Zero-Trust infrastructure. Using SystemD, you might be able to achieve zero-trust by tracking the playbook changes on a Git repository.
- Puppet: Puppet is a pull-based tool, and it requires a Puppet server and agents to configure the servers, and the agents pull the instructions from the Puppet server. It's quite heavy and uses Ruby/Puppet DSL as configuration language. I'm not experienced enough to tell if Puppet is able to achieve zero-trust infrastructure, but what I'm certain is it is quite complex, and it's not entirely Open Source.
- Chef: Chef is a pull-based tool, and it requires a Chef server and agents to configure the servers, and the agents pull the instructions from the Chef server. And, same as Puppet, it's quite heavy and uses Ruby as configuration language. I'm not experienced enough to tell if Chef is able to achieve zero-trust infrastructure, but what I'm certain is it is quite complex, and it's not entirely Open Source.
- SaltStack: SaltStack is a pull-based tool, and it requires a SaltStack server and agents to configure the servers, and the agents pull the instructions from the SaltStack server. It's quite heavy and uses Python as configuration language. I'm not experienced enough to tell if SaltStack is able to achieve zero-trust infrastructure, but what I'm certain is it is quite complex, and it's not entirely Open Source.
As you can see, I'm not very experienced with Chef, Puppet, and SaltStack. And the reason is simple, they are not newbie friendly and certainly doesn't try to be "Zero-Trust" first.
However, for all of these tools, something is very clear:
- They are not designed to be "Zero-Trust" first.
- They wrap their modules around tools, which means they are sensitive to breaking change. I'm not even sure if they work on Gentoo Linux.
- Some of them are not entirely Open Source.
In these recent years, supply chain attacks have been more and more common. Every non-Open Source, non-standard tool is a potential threat. This is why I'm trying to avoid using them. SystemD is stable, and git is stable. They are no reason to not use them.
"What about state recovery and inventory? For example, I want to deploy a Ceph infrastructure."
Quite the question. About state recovery, using my method, you'll have to do it yourself. Compared to existing tool like Ansible, they have already made modules about state recovery. One option is to combine Ansible and SystemD like I said earlier. You would use a service to pull the Ansible playbook and execute it. Honestly, the best way is to set up a stateless OS with minimal tooling to reduce dramatically the attack surface. The second option is to back up the OS before pushing a Git config (which no one will do). The third option is to configure a "teardown" stage in the gitops.sh script. If you want to think more like the "Kubernetes"-way, the fourth option is to configure a "reconcilement" stage in the gitops.sh script.
On Kubernetes, there are controllers that are able to "reconcile" the state of the cluster. The most famous one is the Deployment. The Deployment controller is able to reconcile the state of the cluster by comparing the desired state with the actual state. If the actual state is different from the desired state, the Deployment controller will apply the changes to the cluster.
Developing a controller is often to implement two things:
- The specification of the resource. The specification is the desired state of the resource.
- The reconciliation loop. The reconciliation loop is the process of comparing the actual state of the resource with the desired state and applying the changes to the resource if necessary.
This is very common, especially when developing an Operator. An Operator is a Kubernetes controller that is able to manage a custom resource. Software DevOps/Platform engineers often develop an Operator to manage a custom resource that is specific to their application (a smart-contract from the Ethereum blockchain for example).
If we were to develop this "reconcilement" stage, we would need to develop the specification first. This could become very complex, so it's better to develop in another programming language. Ansible uses an "inquiring" strategy to compare the desired state with the actual state. Whether it's a good idea to use Ansible for this is another question.
About inventory, you can use hostname in the scripts to create node specific configuration. If you want to work with "tags", just do some Bash programming. After all, Ansible is just some Python programming.
And about Ceph, well... Ceph does not recommend Ansible anymore, and they recommend Cephadm and Rook. I recommend using Rook too since I've used it personally, and it's quite stable. Using ArgoCD or Flux, you could do GitOps with Rook.
In reality, if I'm starting an infrastructure from scratch, I would deploy a Kubernetes cluster with K0s since their configuration is declarative, which allows push-based GitOps (but we configure our Kubernetes only when deploying or upgrading it, it's not that frequent and that requires admin privileges). Then, I would use ArgoCD or Flux to deploy my application, Rook to deploy Ceph, KubeVirt to deploy VMs, MetalLB to deploy a LoadBalancer, ... You name it.
By the way, did you know that is blog is deployed using GitOps? I don't have to access my Kubernetes server to deploy a new version of this blog. Also, since GitOps is too heavy, I'm simply using a CronJob with a Kubernetes Service Account to refresh my Deployment. Isn't that cool?
Anyway, I hope you enjoyed this article. If you have any questions, feel free to email me.