Migration from K3OS to K3s and post-mortem of an incident caused by a corrupted SQLite database.
Wednesday 18 December 2024 · 22 mins read · Viewed 1.1k timesTable of contents 🔗
Introduction 🔗
My cluster finally crashed! Let's goooooo! A little of context: I'm running a small k3s cluster with 3 Raspberry Pi 4 with a network storage, and I'm using SQLite as a database for my applications.
In the last two weeks, I've been migrating away from k3os. Reasons are multiple:
- The project is not maintained anymore. However, I could try to maintain it.
- But... many libraries has to be maintained, which I still could try to maintain them.
- Until I found out it was complex to debug when it crashed on my Raspberry Pi... without screen.
- K3os is not purely immutable. It's more of a "read-only" system. Because of this, upgrading the OS (core libraries) and the kernel is a pain.
So what can I do? Well, at the beginning, I wanted to migrate Talos Linux as they actually use SquashFS as root filesystem. But I found the jump too big, so I did a small step: K3s.
Migrating from K3os to K3s 🔗
Move PVCs to network storage 🔗
First step: Migrating ANY storage to the network storage. At the same time, I've replaced the volumes using IP addresses to use DNS, which will help when upgrading the storage node.
The way you do this is very simple. Connect to the storage node, and copy the data to the new location. Then, create new PVs and PVCs, and attach them to the pods. Delete the old PVCs and PVs.
DO NOT DELETE THE PVCs BEFORE COPYING THE DATA! IF YOU FEAR DATA LOSS, JUST DONT DELETE THE PVCs UNTIL THE VERY END!
Migrating workers 🔗
Second step: Migrating workers. This was quite simple. I just had to remove the old workers from Kube and add the new ones. But more precisely, these are the steps I've done:
-
Cordon all the nodes to avoid node overload. Downtime is expected. In a pure production environment, a new node should be added to the cluster before draining the old one.
1kubectl cordon <node> -
Drain the node.
1kubectl drain <node> -
Eject the node from the cluster.
1kubectl delete node <node> -
Eject the SD, format, flash RaspiOS Lite and install K3s.
1curl -sfL https://get.k3s.io | K3S_URL=https://myserver:6443 K3S_TOKEN=mynodetoken sh -
Migrating the master 🔗
WAIT! I recommend taking your time here and do periodic backups of your SQLite database on a long period to have many backups.
The master migration and backup use the same principle:
-
Backup the SQLite database with WAL (File-based backup). This could cause some issues due to locks, but it will be one way to backup the database.
1rsync -av <src>:/var/lib/rancher/k3s/server/db <dest>Normally, the Write-Ahead Logging (WAL) files should avoid data corruption during a backup and restore.
-
Backup the SQLite database with
sqlite3(Logical backup). This is the best way to backup the database.1sqlite3 "/var/lib/rancher/k3s/server/db/state.db" ".backup '$BACKUP_SQLITE_FILE'" -
Backup the token:
1rsync -av /var/lib/rancher/k3s/server/token <dest>
TL;DR: Here's a Kubernetes CronJob:
1apiVersion: batch/v1
2kind: CronJob
3metadata:
4 name: k3s-db-backup
5spec:
6 schedule: '0 0 * * *' # Runs every day at midnight
7 jobTemplate:
8 spec:
9 template:
10 spec:
11 priorityClassName: system-cluster-critical
12 tolerations:
13 - key: 'CriticalAddonsOnly'
14 operator: 'Exists'
15 - key: 'node-role.kubernetes.io/control-plane'
16 operator: 'Exists'
17 effect: 'NoSchedule'
18 - key: 'node-role.kubernetes.io/master'
19 operator: 'Exists'
20 effect: 'NoSchedule'
21 nodeSelector:
22 node-role.kubernetes.io/control-plane: 'true'
23 containers:
24 - name: k3s-db-backup
25 image: alpine:latest
26 imagePullPolicy: IfNotPresent
27 env:
28 - name: AWS_ACCESS_KEY_ID
29 valueFrom:
30 secretKeyRef:
31 name: backup-secret
32 key: access-key-id
33 - name: AWS_SECRET_ACCESS_KEY
34 valueFrom:
35 secretKeyRef:
36 name: backup-secret
37 key: secret-access-key
38 - name: AWS_DEFAULT_REGION
39 valueFrom:
40 secretKeyRef:
41 key: region
42 name: backup-secret
43 - name: AWS_S3_ENDPOINT
44 valueFrom:
45 secretKeyRef:
46 key: s3-endpoint
47 name: backup-secret
48 - name: AWS_S3_BUCKET
49 valueFrom:
50 secretKeyRef:
51 key: s3-bucket
52 name: backup-secret
53 - name: AWS_S3_PATH
54 valueFrom:
55 secretKeyRef:
56 key: s3-path
57 name: backup-secret
58 volumeMounts:
59 - name: gpg-passphrase
60 mountPath: /etc/backup
61 readOnly: true
62 - name: backup-dir
63 mountPath: /tmp/backups # Directory for temporary backup files
64 - name: db-dir
65 mountPath: /host/db # K3s database directory
66 readOnly: true
67 command: ['/bin/ash', '-c']
68 args:
69 - |
70 set -ex
71
72 # Install dependencies
73 apk add --no-cache zstd gnupg aws-cli sqlite
74
75 # Define backup file paths
76 BACKUP_DIR="/host/db"
77 SQLITE_DB="$BACKUP_DIR/state.db"
78 TIMESTAMP=$(date +"%Y-%m-%d_%H-%M-%S")
79 BACKUP_FILE="/tmp/backups/k3s_db_$TIMESTAMP.tar.zst"
80 BACKUP_SQLITE_FILE="/tmp/backups/state_$TIMESTAMP.db"
81 ENCRYPTED_FILE="$BACKUP_FILE.gpg"
82 ENCRYPTED_SQLITE_FILE="$BACKUP_SQLITE_FILE.gpg"
83 S3_BUCKET="$AWS_S3_BUCKET"
84 S3_PATH="$AWS_S3_PATH"
85 S3_ENDPOINT="$AWS_S3_ENDPOINT"
86
87 # Configure AWS CLI with custom endpoint and credentials
88 mkdir -p ~/.aws
89 cat > ~/.aws/config <<EOF
90 [default]
91 region = $AWS_DEFAULT_REGION
92 output = json
93 services = default
94 s3 =
95 max_concurrent_requests = 100
96 max_queue_size = 1000
97 multipart_threshold = 50 MB
98 multipart_chunksize = 10 MB
99
100 [services default]
101 s3 =
102 endpoint_url = $S3_ENDPOINT
103 EOF
104
105 cat > ~/.aws/credentials <<EOF
106 [default]
107 aws_access_key_id = $AWS_ACCESS_KEY_ID
108 aws_secret_access_key = $AWS_SECRET_ACCESS_KEY
109 EOF
110
111 # Compress the database directory (File-based backup)
112 tar -cf - -C "$BACKUP_DIR" . | zstd -q -o "$BACKUP_FILE"
113
114 # Encrypt with GPG
115 gpg --batch --yes --passphrase-file /etc/backup/gpg-passphrase --cipher-algo AES256 -c -o "$ENCRYPTED_FILE" "$BACKUP_FILE"
116
117 # Change permissions for the encrypted file
118 chmod 600 "$ENCRYPTED_FILE"
119
120 # Upload to S3 using custom endpoint
121 aws s3 cp "$ENCRYPTED_FILE" "s3://$S3_BUCKET/$S3_PATH/$(basename $ENCRYPTED_FILE)"
122
123 # Cleanup (remove the backup, compressed, and encrypted files)
124 rm -f "$BACKUP_FILE" "$ENCRYPTED_FILE"
125
126 # Do a sqlite3 backup
127 sqlite3 "$SQLITE_DB" ".backup '$BACKUP_SQLITE_FILE'"
128
129 # Encrypt the sqlite3 backup
130 gpg --batch --yes --passphrase-file /etc/backup/gpg-passphrase --cipher-algo AES256 -c -o "$ENCRYPTED_SQLITE_FILE" "$BACKUP_SQLITE_FILE"
131
132 # Change permissions for the encrypted sqlite3 file
133 chmod 600 "$ENCRYPTED_SQLITE_FILE"
134
135 # Upload to S3 using custom endpoint
136 aws s3 cp "$ENCRYPTED_SQLITE_FILE" "s3://$S3_BUCKET/$S3_PATH/$(basename $ENCRYPTED_SQLITE_FILE)"
137
138 # Cleanup (remove the sqlite3 backup, compressed, and encrypted files)
139 rm -f "$BACKUP_SQLITE_FILE" "$ENCRYPTED_SQLITE_FILE"
140
141 restartPolicy: OnFailure
142 volumes:
143 - name: gpg-passphrase
144 secret:
145 secretName: backup-secret
146 defaultMode: 0400
147 items:
148 - key: gpg-passphrase
149 path: gpg-passphrase
150 - name: backup-dir
151 emptyDir: {} # Empty directory to hold temporary files like backups
152 - name: db-dir
153 hostPath:
154 path: /var/lib/rancher/k3s/server/db
155 type: Directory
156
It does not backup the token.
After the backup, if you have an SD card laying around, you can flash it with RaspiOS Lite and install K3s. Then, you can restore the database and the token.
1rsync -av <src>/db/ <dst>:/var/lib/rancher/k3s/server/db/
2rsync -av <src>/token <dst>:/var/lib/rancher/k3s/server/token
3chown -R root:root /var/lib/rancher/k3s/server/db
Post-mortem of the crash 🔗
Summary 🔗
First, the crash didn't happen immediately but after two days of a working cluster. The crash was actually almost invisible and was "accumulating" over time.
The crash was caused by a corrupted SQLite database, possibly due to a permission issue (it was pi:pi...), or a CPU overload.
Leadup 🔗
The first symptom was that the backups were bigger than usual. 53.89 MB (compressed), then 80.51 MB, then 228.3 MB.
The second symptom was the controller was beginning to be unresponsive. Scheduling was slow and metrics didn't reach the Prometheus server. At this point, the visibility was beginning to be low.
The third symptom was high CPU usage.
The fourth symptom was the logs having issues with sqlite: "Slow SQL". You know you're in trouble when you see this.
Detection 🔗
If you have proper alerts set up, you would have been immediately alerted as the CPU is being overloaded:
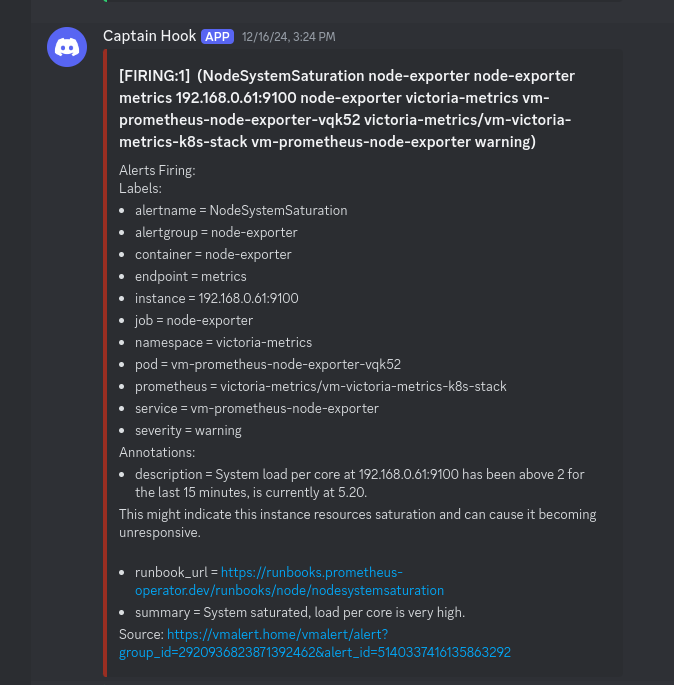
The question is: "Is it a simple burst? Or is it really being overloaded?". And so, I checked.
Recovery 🔗
First, Grafana... which shows nothing, weird.
Then, htop, which shows k3s server taking half of the CPU. Huh, maybe it's because there too many pods on the controller?
Finally, I drain and cordon the controller. k3s server was still high, and by checking syslogs... it was weirder.
So, I did a health check on the SQLite database:
1sqlite3 state.db "PRAGMA integrity_check"
which fails: Error: database disk image is malformed.
Testing recovering the DB:
1sqlite3 broken.db ".recover" | sqlite3 new.db
2# And
3sqlite3 mydata.db ".dump" | sqlite3 new.db
which fail!
At this point, I had no choice but to restore a backup of the DB... which works!
It's at this point I found out that the permissions of the state.db were pi:pi instead of root:root. Was that really the root cause?
Permanent fix 🔗
After the recovery, the DB crashed again, but without corruption. The DB grown up to 1.5 GB. There is issue, which propose this fix:
1sqlite3 state.db
2
3sqlite> delete from kine where id in (select id from (select id, name from kine where id not in (select max(id) as id from kine group by name)));
4sqlite> vacuum;
5sqlite> .quit
Which could be a permanent fix. The issue is that the compaction is failing hard, and there are zombie containers spamming the DB.
Lesson learned and corrective actions 🔗
I learned this:
- Better backup and restore logical backups than SQLite files.
- Migrating and restoring K3s is easy! Just put the backup and BAM, it works! Migrating between K3s distribution is super easy. Maybe it is worth trying MicroOS?
- Compact your SQLite database.
Lastly, you are probably wondering why I didn't migrate to ETCD?
As someone who worked on distributed systems, I can easily tell you why:
- SQLite with WAL is VERY performant, more performant than PostgreSQL.
- I don't have HA nodes. ETCD, through the Raft Consensus algorithm, is able to achieve HA by replicating the WAL across the nodes. You must have 3 HA nodes to make that algorithm works.
Now, for the corrective actions... A new storage node is coming, a Raspberry Pi 5 in fact, and I plan to use it to run databases instead of just running NFS. This avoid overhead and only exposes processed data during communications.
This also means I will need to migrate from CockroachDB to the good ol' PostgreSQL!
At the end of the day, this will reduce CPU loads on the controller and I will be able to apply a taint to exclude the controller from running CPU intensive workloads.