Pushing my Home Raspberry Pi cluster into a production state
Saturday 25 January 2025 · 40 mins read · Viewed 659 timesTable of contents 🔗
Introduction 🔗
New year, new budget, new hardware. I've upgraded my home Raspberry Pi cluster with a new storage node, a new router, new OSes and new services.
If you read my last article on my home Raspberry Pi cluster, you may know that I was looking to upgrade the storage node and router. Well that's what I did, and did a lot more since then.
Hardware overhaul 🔗
Replacing the router 🔗
The setup of my cluster was the following:
- Nodes are interconnected with each other via one switch to use the whole 1Gbps bandwidth.
- To connect the nodes to the internet, I've used a wireless "router"... but in reality this is a Raspberry Pi 3+ which acts as a router.
Small issue: the wireless bandwidth of the Raspberry Pi is very limited.
Luckily, the whole house network has been upgraded to Wi-Fi 6E using a dual TP Link Deco XE75 setup, which replaced the old repeater and gave me a new wireless router: a D-Link router with OpenWRT.
I managed to replace the RPi router by using the "Wi-Fi Extender/Repeater with relayd" setup, without the repeater feature (disabled Access-Point):
1config interface 'lan' # Management interface
2 option device 'br-lan'
3 option proto 'static'
4 option ipaddr '192.168.2.1'
5 option netmask '255.255.255.0'
6 option ip6assign '60'
7
8config interface 'wwan' # Use to connect to the modem
9 option proto 'dhcp'
10
11config interface 'repeater_bridge' # Relay interface
12 option proto 'relay'
13 option network 'lan wwan'
1config wifi-device 'radio0' # 5GHz band, used to connect to the modem.
2 option type 'mac80211'
3 option path 'pci0000:00/0000:00:00.0'
4 option band '5g'
5 option htmode 'VHT80'
6 option disabled '0'
7 option country 'FR' # This is important! Based on the country, the wrong band might be used.
8
9config wifi-iface 'default_radio0'
10 option device 'radio0'
11 option network 'wwan'
12 option mode 'sta'
13 option ssid '[REDACTED]'
14 option encryption 'psk2'
15 option key '[REDACTED]'
16
17config wifi-device 'radio1' # 2.4 GHz band, which can be used as AP.
18 option disabled '1'
19
20config wifi-iface 'default_radio1'
21 option device 'radio1'
22 # Interface is disabled.
1config zone
2 option name 'lan'
3 option network 'lan repeater_bridge wwan'
4 option input 'ACCEPT'
5 option output 'ACCEPT'
6 option forward 'ACCEPT'
The setup gave me the following results with iperf3:
- Around 160Mbps in download speed (cluster ← world).
- Around 70Mbps in upload speed (world → cluster).
Which seems small, but considering it's wireless and faster than the old setup, it's pretty good.
Adding the storage node 🔗
My old storage node is an ODroid XU4. It doesn't have enough RAM to cache data over NFS. So, I need to set up a new storage node. To avoid also sending a lot of data over a small "channel", I will prefer to have some computing power on the storage node to only exposed processed data. Therefore, I will use a two tier storage setup.
The reason being that I will prefer a two tier storage setup:
- The
slowtier: the ODroid XU4, running on SATA SSDs, which is good for archiving, hosting videos, etc. - The
fasttier: the new storage node, a Rapsberry Pi 5 with NVME SSDs, which is good for storage, but also for computing, giving me the power to host PostgreSQL databases, LDAP, etc.
Therefore, I'm replacing CockroachDB with a simple PostgreSQL setup (especially since CockroachDB decided to close the free tier). And this also means I'm installing k3s on the new node, but without k3os.
Replacing k3os with simple RaspiOS with k3s 🔗
K3OS is dead, but it's been dead for a long time (2 years at least). However, I tried to maintain a fork of k3os, but it is at that moment I saw some issues.
At the very beginning, I used this project: picl-k3os-image-generator, which is a way to generate k3os images with Busybox as base.
This project added these issues:
- Busybox is not updated during k3os upgrade. In fact, k3os upgrades were simply k3s upgrades.
- The kernel didn't also update and used the initial kernel that was installed with the image generator.
Basically, the OS of the Raspberry Pi didn't update during the last 3 years. But, obviously, I tried to update them, however the manipulation isn't worth it:
- You need to eject the SD cards of the Raspberry Pi.
- Download the latest RaspiOS image and extract the kernel and firmware.
- Install the new kernel and firmware.
- Reinstall the SD card and boot.
The simple fact that I have to manually install the kernel negates the whole point of k3os: to have an immutable OS.
Therefore, I will use a simple RaspiOS image with k3s, which permits kernel and firmware updates via apt. The installation process was the following:
- Cordon and drain every nodes.
- Remove any plan from the
system-upgrade-controller. - Backup
/var/lib/rancher/k3s/server/tokenand/var/lib/rancher/k3s/server/db/(I recommend to back up files and also use the sqlite3 backup utility). - Install RaspiOS.
- (controller) Restore
/var/lib/rancher/k3s/server/tokenand/var/lib/rancher/k3s/server/db/. - Install k3s.
- It's good to go!
By the way, you may need to vacuum the sqlite database (make sure to backup before that). The commands are:
1sqlite3 state.db
2
3sqlite> delete from kine where id in (select id from (select id, name from kine where id not in (select max(id) as id from kine group by name)));
4sqlite> vacuum;
5sqlite> .quit
This could repair some issues with the database and k3s. After the migration, I come back to the old style of infrastructure management: mutable OSes... which means I need to setup Ansible.
Software overhaul 🔗
Ansible 🔗
Wait what? There wasn't ansible before?
Yes, in fact, when you setup an immutable infrastructure, the idea is that everything is declarative, including the OS configuration like Kernel version, installed software.
If you declaratively deploy a Kubernetes cluster (like using Terraform on Google Cloud, or K0sctl with K0s on your own infrastructure), the only tools needed is your deployment software (Terraform or K0sctl) and Kubectl.
But since we switched to using a mutable infrastructure (mutable OSes), we need to configure the software installed on the nodes.
Therefore, I've setup Ansible with simply two roles:
roles/storageto format the storage node.roles/upgrade_and_rebootto upgrade the OS and reboot the node.
And that's it! We can also add the k3s install process in the cluster, however, I setup the k3s upgrade controller on Kubernetes which can self-upgrade the cluster.
Basically, my rules are:
- If it can be handled with Kubernetes (like CronJobs), use Kubernetes.
- If it is at almost infrastructure level, use Ansible.
Migrating CockroachDB to PostgreSQL 🔗
Since, CockroachDB is no more free, I will simply switch to PostgreSQL with backups. CockroachDB uses too many CPUs and RAM while I expected a low usage, especially when using the Raft consensus. CockroachDB not being fully PostgreSQL-API compatible means that its implementation is certainly doubtful.
So... during my search I was looking for a method to migrate CockroachDB data to PostgreSQL... in which, none work.
So here's my method, which is a lot of work, but it works with certainty.
The method is the following. Let's say you want to migrate the data of Service A:
-
Deploy PostgreSQL on the production cluster.
-
To avoid any downtime, deploy Service A locally and connect it to PostgreSQL. This will run proper DB migrations, and therefore, fix any issues with the SQL schema.
-
Then, use DBeaver to export data:
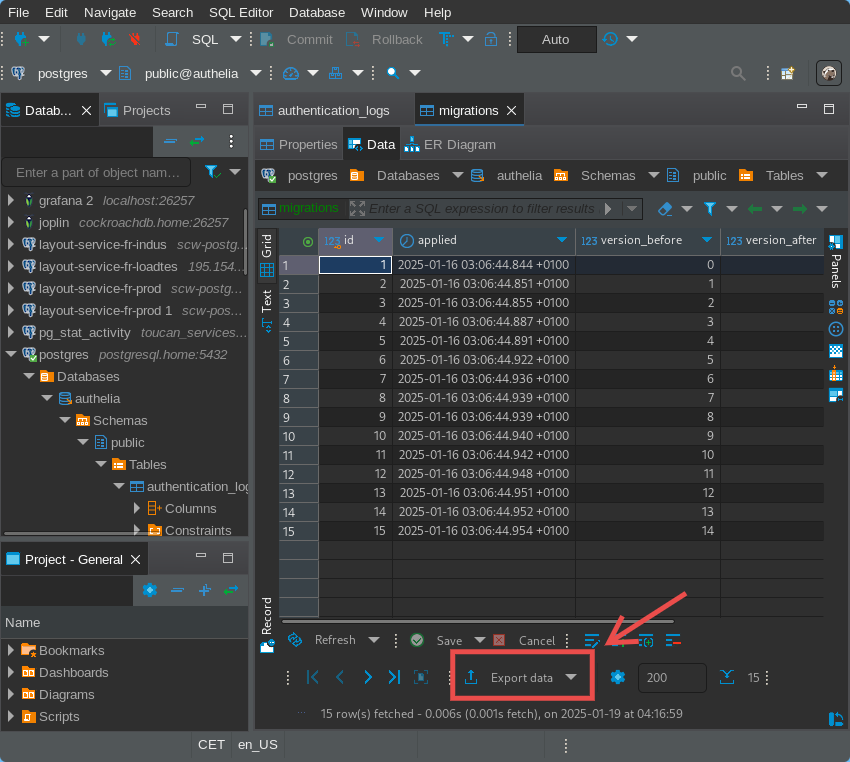 WARNING
WARNINGDon't forget to also export the sequences!
-
And finally, reconnect the production Service A to PostgreSQL.
That's all, do note I don't have many services running on CockroachDB, only Grafana and VaultWarden. But now, I'm running a lot of services!
New services, and death to some 🔗
FluxCD 🔗
I've talked about it in an older article, but didn't really officialize it. That's because I was still doubting of FluxCD's capabilities.
Today, I can finally say that FluxCD is the best lightweight and fully-featured GitOps solution. I had zero issues with it during the 4 past months.
The issues I've talked about in the past were:
- FluxCD is not clever about Helm Chart. But in reality, this is because I used the subchart pattern which works with ArgoCD. What I've done instead is simply using the chart with the release tag, and if I need to patch it, I can simply write manifests alongside the Helm release thanks to FluxCD capabilities. (It's difficult to explain, but let's say simply there is no need for
kustomized-helmwith FluxCD.) - Capacitor is slow. And it is still slow, but with the notifications setup and Flux CLI installed, I'm simply not using capacitor anymore.
LLDAP 🔗
I've always hated LDAP and the existing implementations:
- OpenLDAP: too complex to configure, too many "runtime" configuration.
- FreeIPA: too complex and fat.
- 389ds: actually pretty damn good, but there are also runtime configuration issues.
However, there is now LLDAP, a lightweight LDAP implementation which does exactly what you need: a user database with preconfigured schemas.
LLDAP can use PostgreSQL as DB and has a small UI:
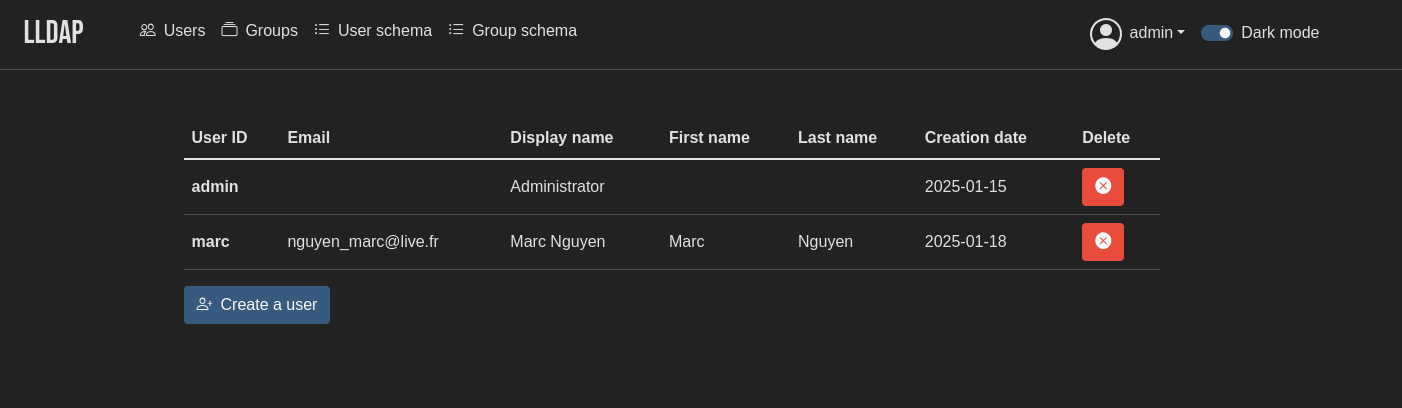
I will be using LLDAP to unify the authentication layer of my services, especially since I want to use that as user DB for Authelia.
Authelia 🔗
Authelia is lightweight authentication server. It is an OIDC provider and is also able to handle ForwardAuth requests.
It does NOT support sign up, so it is mainly used for internal authentication. It uses Postgres as DB for Authentication method storage, and LDAP as user DB.
And that's it. It's simple, stateless and highly scalable. It doesn't have any admin UI, but has a personal user page:
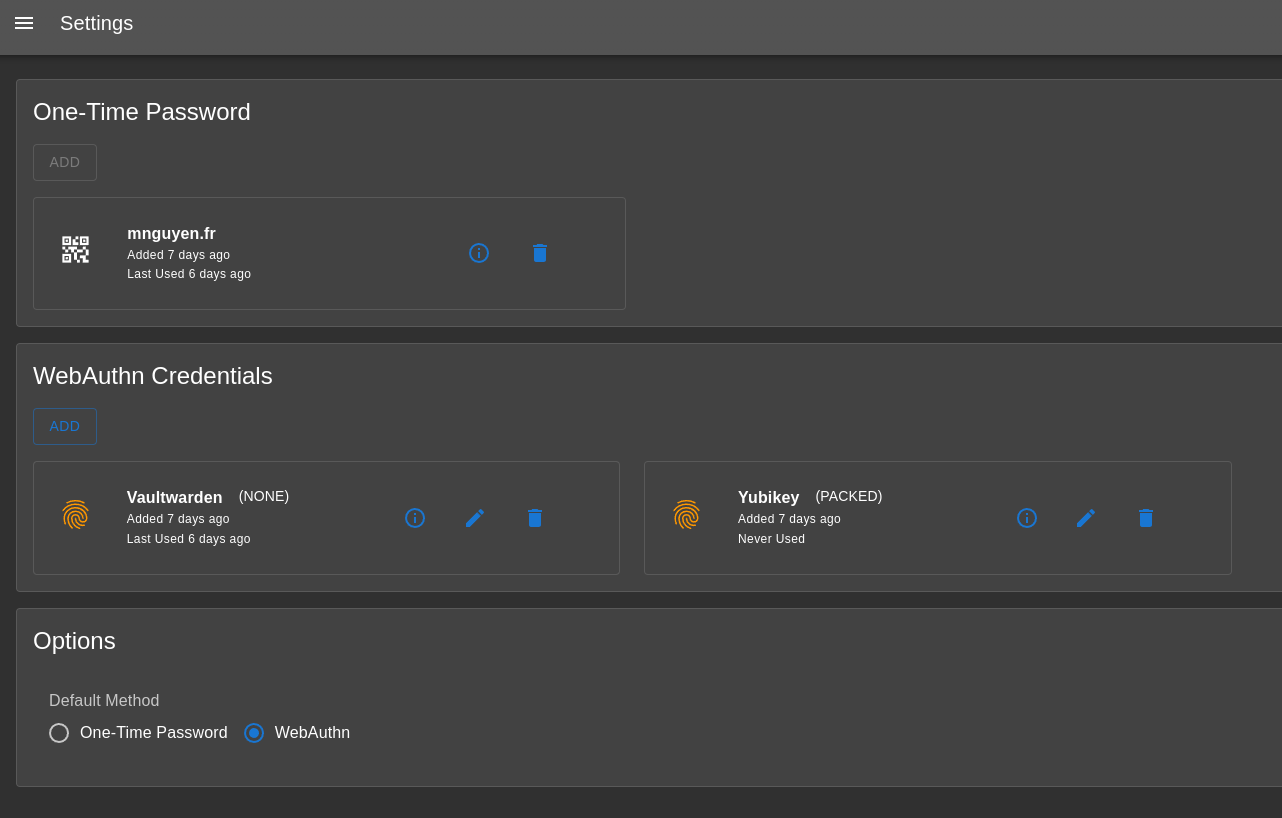
Authelia can be configured with a simple YAML file.
Crowdsec 🔗
To ban bots and use crowdsourced blocklists, I've setup Crowdsec.
The setup is the following:
- Parsers are installed alongside Traefik to parse the logs.
- The Local API fetch the information from the parsers and make decisions.
- Bouncers are installed on Traefik (or on Linux, but I didn't do that since the only entrypoint to my cluster is through HTTP, and not SSH and cie.).
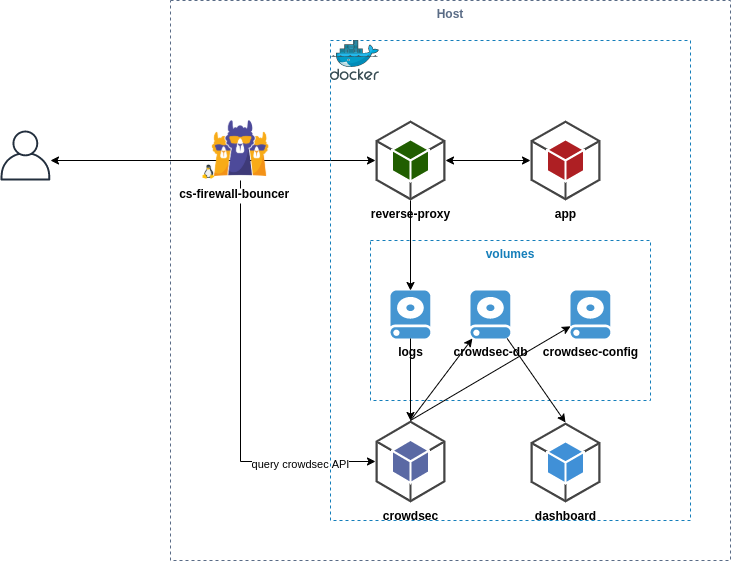
I've also configured Traefik to give JSON logs so that I can analyze it on Grafana.
VictoriaLogs and Vectors 🔗
Now that I have computing power on my storage node, not only did I migrate my VictoriaMetrics instance on it, but I've also added VictoriaLogs.
VictoriaLogs is an alternative to Grafana Loki and Elasticsearch, but it highly-optimised for logs and doesn't use a lot of memory, CPU and storage. It doesn't need any custom index and it's super fast.
Here's its usage with ~80 services running on the cluster, all of them logged on VictoriaLogs:
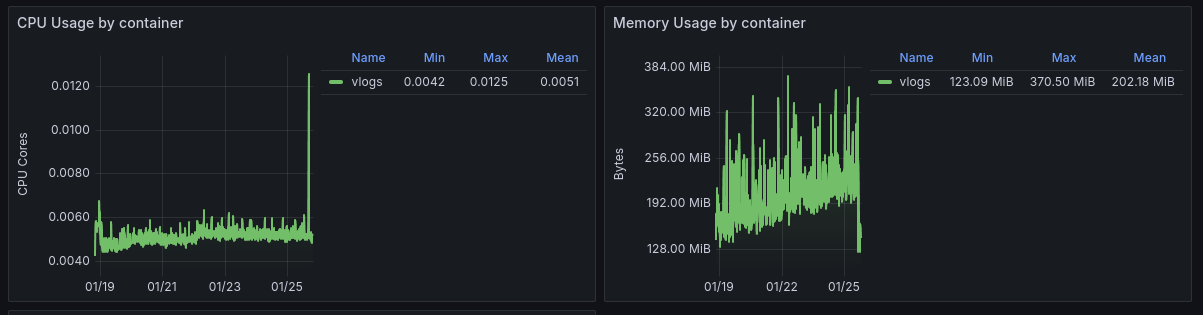
It doesn't go above 384 MiB of RAM, and certainly doesn't use above 100m of CPU!
Now, about the agents. I use Vectors to fetch Kubernetes logs. Its configuration is dead simple:
1data_dir: /vector-data-dir
2api:
3 enabled: false
4 address: 0.0.0.0:8686
5 playground: true
6enrichment_tables:
7 gip:
8 type: geoip
9 path: /geoip/GeoLite2-City.mmdb
10sources:
11 k8s:
12 type: kubernetes_logs
13 internal_metrics:
14 type: internal_metrics
15transforms:
16 parser:
17 type: remap
18 inputs: [k8s]
19 source: |
20 structured, err = parse_json(.message)
21 if err == null {
22 . = merge!(., structured)
23 }
24 routes:
25 type: route
26 inputs: [parser]
27 route:
28 traefik: '.kubernetes.container_name == "tail-accesslogs" && contains(to_string(.kubernetes.pod_name) ?? "", "traefik")'
29 reroute_unmatched: true # Send unmatched logs to routes._unmatched stream
30 traefik:
31 type: remap
32 inputs: [routes.traefik]
33 source: |
34 # Enrich with geoip data
35 geoip, err = get_enrichment_table_record("gip", { "ip": .ClientHost }, ["country_code","latitude","longitude"] )
36 if err == null {
37 if is_array(geoip){
38 geoip = geoip[0]
39 }
40 if geoip != null {
41 .geoip = geoip
42 }
43 }
44sinks:
45 exporter:
46 type: prometheus_exporter
47 address: 0.0.0.0:9090
48 inputs: [internal_metrics]
49 vlogs:
50 type: elasticsearch
51 inputs: [routes._unmatched, traefik]
52 endpoints: << include "vlogs.es.urls" . >>
53 mode: bulk
54 api_version: v8
55 compression: gzip
56 healthcheck:
57 enabled: false
58 request:
59 headers:
60 VL-Time-Field: timestamp
61 VL-Stream-Fields: stream,kubernetes.pod_name,kubernetes.container_name,kubernetes.pod_namespace
62 VL-Msg-Field: message,msg,_msg,log.msg,log.message,log
63 AccountID: '0'
64 ProjectID: '0'
65
With this configuration, logs are collected from Kubernetes, parsed as JSON (if compatible), and routed based on conditions (e.g., logs from Traefik). GeoIP enrichment is applied to Traefik logs using a GeoLite2 database to add geolocation data. Unmatched logs and enriched Traefik logs are sent to VictoriaLogs, while internal metrics are exported to Prometheus for monitoring.
Parsing these logs on Grafana give these results:
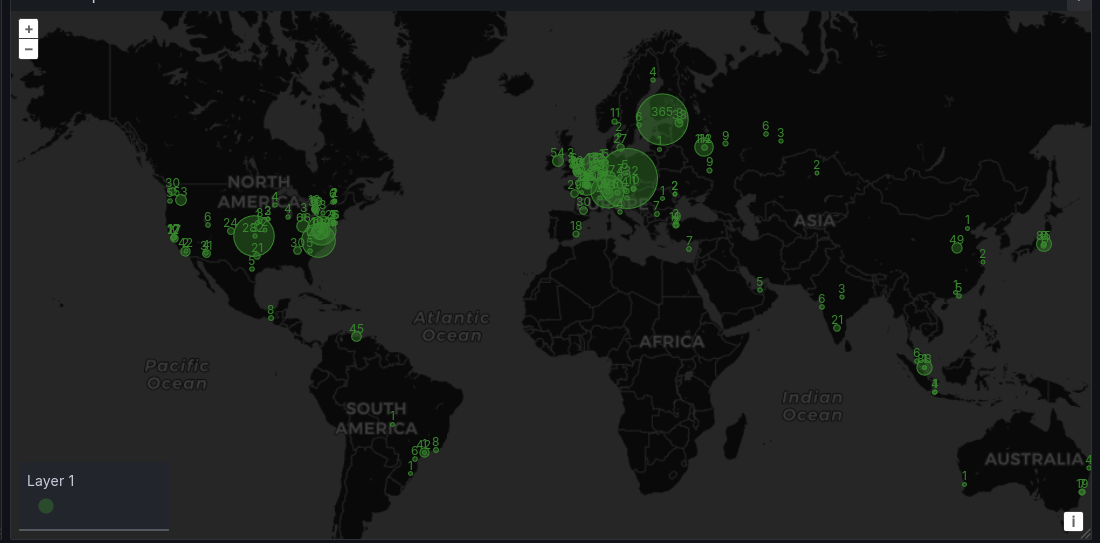
Pretty great, yeah? Also it's over 30 days of data, and the query is instant.
It can give a pretty precise insight:
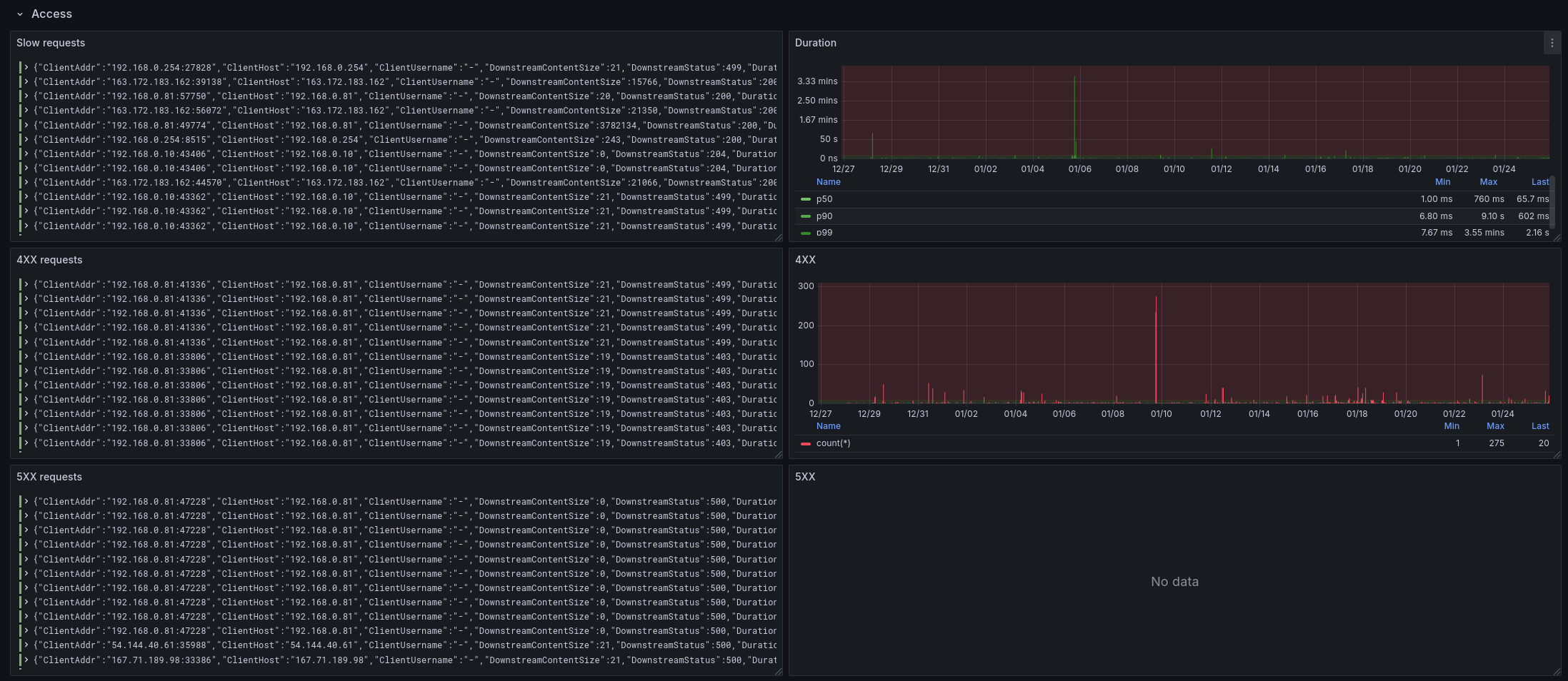
ArchiSteamFarm 🔗
Lastly, I'm selfhosting ArchiSteamFarm. Hey! I need have a lot of games, okay? I could sells those useless cards and buy games that I actually want.
Tried self-hosting a mail server with Maddy, using Scaleway Transactional mail instead 🔗
I tried to selfhost my own mailserver since Authelia requires to setup SMTP for "Password reset" mails.
However, residential IPs are banned, there this was useless (it still worked though).
Instead, I switched to Scaleway Transactional Mails since it's free for the first 300 mails and I have my domain there. Also, due to SMTP constraints, I'v also enabled DNSSEC, so, basically, everything was optimized to use Scaleway.
It also has autoconfiguration. Life is great.
Backups and AWS mountpoint S3 CSI Driver 🔗
Lastly, I've setup backups everywhere and used Scaleway S3 offering. Obviously, I have encrypted the backups.
Something that I didn't know, but helped like hell, is using mountpoint-s3 (like s3fuse) as CSI driver.
With this, I can upload backups to S3 without the need to install awscli or s3cli, and simply use cp.
Postgres backup
1apiVersion: batch/v1
2kind: CronJob
3metadata:
4 name: postgresql-read-pgdumpall
5 namespace: postgresql
6 labels:
7 app.kubernetes.io/component: pg_dumpall
8 app.kubernetes.io/instance: postgresql
9 app.kubernetes.io/managed-by: Helm
10 app.kubernetes.io/name: postgresql
11 app.kubernetes.io/version: 17.2.0
12 helm.sh/chart: postgresql-16.4.5
13 helm.toolkit.fluxcd.io/name: postgresql
14 helm.toolkit.fluxcd.io/namespace: flux-system
15 annotations:
16 meta.helm.sh/release-name: postgresql
17 meta.helm.sh/release-namespace: postgresql
18spec:
19 schedule: '@daily'
20 concurrencyPolicy: Allow
21 suspend: false
22 jobTemplate:
23 metadata:
24 spec:
25 template:
26 metadata:
27 labels:
28 app.kubernetes.io/component: pg_dumpall
29 app.kubernetes.io/instance: postgresql
30 app.kubernetes.io/managed-by: Helm
31 app.kubernetes.io/name: postgresql
32 app.kubernetes.io/version: 17.2.0
33 helm.sh/chart: postgresql-16.4.5
34 spec:
35 volumes:
36 - name: raw-certificates
37 secret:
38 secretName: postgresql.internal.home-cert
39 defaultMode: 420
40 - name: datadir
41 persistentVolumeClaim:
42 claimName: postgres-backups-pvc
43 - name: empty-dir
44 emptyDir: {}
45 - name: tmp
46 emptyDir: {}
47 containers:
48 - name: postgresql-read-pgdumpall
49 image: docker.io/bitnami/postgresql:17.2.0-debian-12-r8
50 command:
51 - /bin/sh
52 - '-c'
53 - >
54 DATE="$(date '+%Y-%m-%d-%H-%M')"
55
56 pg_dumpall --clean --if-exists --load-via-partition-root
57 --quote-all-identifiers --no-password
58 --file=/tmp/pg_dumpall-$DATE.pgdump
59
60 mv /tmp/pg_dumpall-$DATE.pgdump
61 ${PGDUMP_DIR}/pg_dumpall-$DATE.pgdump
62 env:
63 - name: PGUSER
64 value: postgres
65 - name: PGPASSWORD
66 valueFrom:
67 secretKeyRef:
68 name: postgresql-secret
69 key: postgres-password
70 - name: PGHOST
71 value: postgresql-read
72 - name: PGPORT
73 value: '5432'
74 - name: PGDUMP_DIR
75 value: /backup/pgdump
76 - name: PGSSLROOTCERT
77 value: /tmp/certs/ca.crt
78 resources:
79 limits:
80 ephemeral-storage: 2Gi
81 memory: 192Mi
82 requests:
83 cpu: 100m
84 ephemeral-storage: 50Mi
85 memory: 128Mi
86 volumeMounts:
87 - name: raw-certificates
88 mountPath: /tmp/certs
89 - name: datadir
90 mountPath: /backup/pgdump
91 - name: empty-dir
92 mountPath: /tmp
93 subPath: tmp-dir
94 imagePullPolicy: IfNotPresent
95 securityContext:
96 capabilities:
97 drop:
98 - ALL
99 privileged: false
100 seLinuxOptions: {}
101 runAsUser: 1001
102 runAsGroup: 1001
103 runAsNonRoot: true
104 readOnlyRootFilesystem: true
105 allowPrivilegeEscalation: false
106 seccompProfile:
107 type: RuntimeDefault
108 restartPolicy: OnFailure
109 terminationGracePeriodSeconds: 30
110 securityContext:
111 fsGroup: 1001
112 successfulJobsHistoryLimit: 3
113 failedJobsHistoryLimit: 1
114---
115apiVersion: v1
116kind: PersistentVolumeClaim
117metadata:
118 name: postgres-backups-pvc
119 namespace: postgresql
120spec:
121 resources:
122 requests:
123 storage: 50Gi
124 volumeMode: Filesystem
125 accessModes:
126 - ReadWriteMany
127 storageClassName: ''
128 volumeName: postgres-backups-pv
129---
130apiVersion: v1
131kind: PersistentVolume
132metadata:
133 name: postgres-backups-pv
134spec:
135 capacity:
136 storage: 50Gi
137 accessModes:
138 - ReadWriteMany
139 storageClassName: ''
140 mountOptions:
141 - prefix postgres-backups/
142 - endpoint-url https://s3.fr-par.scw.cloud
143 - uid=1001
144 - gid=1001
145 - allow-other
146 csi:
147 driver: s3.csi.aws.com
148 volumeHandle: postgres-backups-pv
149 volumeAttributes:
150 bucketName: REDACTED
151
K3s backups
1apiVersion: batch/v1
2kind: CronJob
3metadata:
4 name: k3s-db-backup
5spec:
6 schedule: '0 0 * * *' # Runs every day at midnight
7 jobTemplate:
8 spec:
9 template:
10 spec:
11 priorityClassName: system-cluster-critical
12 tolerations:
13 - key: 'CriticalAddonsOnly'
14 operator: 'Exists'
15 - key: 'node-role.kubernetes.io/control-plane'
16 operator: 'Exists'
17 effect: 'NoSchedule'
18 - key: 'node-role.kubernetes.io/master'
19 operator: 'Exists'
20 effect: 'NoSchedule'
21 nodeSelector:
22 node-role.kubernetes.io/control-plane: 'true'
23 containers:
24 - name: k3s-db-backup
25 image: alpine:latest
26 imagePullPolicy: IfNotPresent
27 volumeMounts:
28 - name: gpg-passphrase
29 mountPath: /etc/backup
30 readOnly: true
31 - name: backup-dir
32 mountPath: /tmp/backups # Directory for temporary backup files
33 - name: db-dir
34 mountPath: /host/db # K3s database directory
35 readOnly: true
36 - name: output
37 mountPath: /out
38 command: ['/bin/ash', '-c']
39 args:
40 - |
41 set -ex
42
43 # Install dependencies
44 apk add --no-cache zstd gnupg sqlite
45
46 # Define backup file paths
47 BACKUP_DIR="/host/db"
48 SQLITE_DB="$BACKUP_DIR/state.db"
49 TIMESTAMP=$(date +"%Y-%m-%d_%H-%M-%S")
50 BACKUP_FILE="/tmp/backups/k3s_db_$TIMESTAMP.tar.zst"
51 BACKUP_SQLITE_FILE="/tmp/backups/state_$TIMESTAMP.db"
52 ENCRYPTED_FILE="$BACKUP_FILE.gpg"
53 ENCRYPTED_SQLITE_FILE="$BACKUP_SQLITE_FILE.gpg"
54
55 # Compress the database directory (File-based backup)
56 tar -cf - -C "$BACKUP_DIR" . | zstd -q -o "$BACKUP_FILE"
57
58 # Encrypt with GPG
59 gpg --batch --yes --passphrase-file /etc/backup/gpg-passphrase --cipher-algo AES256 -c -o "$ENCRYPTED_FILE" "$BACKUP_FILE"
60
61 # Change permissions for the encrypted file
62 chmod 600 "$ENCRYPTED_FILE"
63
64 # Upload to S3 using custom endpoint
65 cp "$ENCRYPTED_FILE" "/out/$(basename $ENCRYPTED_FILE)"
66
67 # Cleanup (remove the backup, compressed, and encrypted files)
68 rm -f "$BACKUP_FILE" "$ENCRYPTED_FILE"
69
70 # Do a sqlite3 backup
71 sqlite3 "$SQLITE_DB" ".backup '$BACKUP_SQLITE_FILE'"
72
73 # Encrypt the sqlite3 backup
74 gpg --batch --yes --passphrase-file /etc/backup/gpg-passphrase --cipher-algo AES256 -c -o "$ENCRYPTED_SQLITE_FILE" "$BACKUP_SQLITE_FILE"
75
76 # Change permissions for the encrypted sqlite3 file
77 chmod 600 "$ENCRYPTED_SQLITE_FILE"
78
79 # Upload to S3 using custom endpoint
80 cp "$ENCRYPTED_SQLITE_FILE" "/out/$(basename $ENCRYPTED_SQLITE_FILE)"
81
82 # Cleanup (remove the sqlite3 backup, compressed, and encrypted files)
83 rm -f "$BACKUP_SQLITE_FILE" "$ENCRYPTED_SQLITE_FILE"
84
85 restartPolicy: OnFailure
86 volumes:
87 - name: gpg-passphrase
88 secret:
89 secretName: backup-secret
90 defaultMode: 0400
91 items:
92 - key: gpg-passphrase
93 path: gpg-passphrase
94 - name: backup-dir
95 emptyDir: {} # Empty directory to hold temporary files like backups
96 - name: db-dir
97 hostPath:
98 path: /var/lib/rancher/k3s/server/db
99 type: Directory
100 - name: output
101 persistentVolumeClaim:
102 claimName: k3s-backups-pvc
103---
104apiVersion: v1
105kind: PersistentVolumeClaim
106metadata:
107 name: k3s-backups-pvc
108spec:
109 accessModes:
110 - ReadWriteMany
111 resources:
112 requests:
113 storage: 50Gi
114 storageClassName: ''
115 volumeName: k3s-backups-pv
116 volumeMode: Filesystem
117---
118apiVersion: v1
119kind: PersistentVolume
120metadata:
121 name: k3s-backups-pv
122spec:
123 capacity:
124 storage: 50Gi
125 accessModes:
126 - ReadWriteMany
127 storageClassName: ''
128 mountOptions:
129 - prefix k3s-backups/
130 - endpoint-url https://s3.fr-par.scw.cloud
131 - uid=1001
132 - gid=1001
133 - allow-other
134 csi:
135 driver: s3.csi.aws.com
136 volumeHandle: k3s-backups-pv
137 volumeAttributes:
138 bucketName: REDACTED
139
Conclusion 🔗
CockroachDB and NFS were the main bottlenecks of my old infrastructure. With a storage node with compute power, my setup is now super efficient. Having also learned to clean my k3s DD, there is no more abnormal CPU usage.
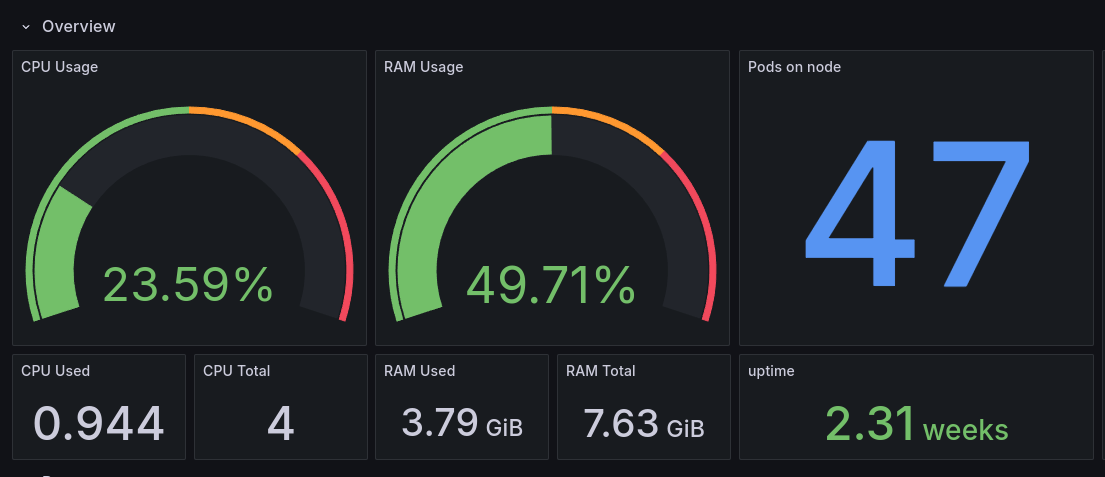
Having my storage node also under Kubernetes, I can install monitoring agents super easily:
Control node
Worker 0
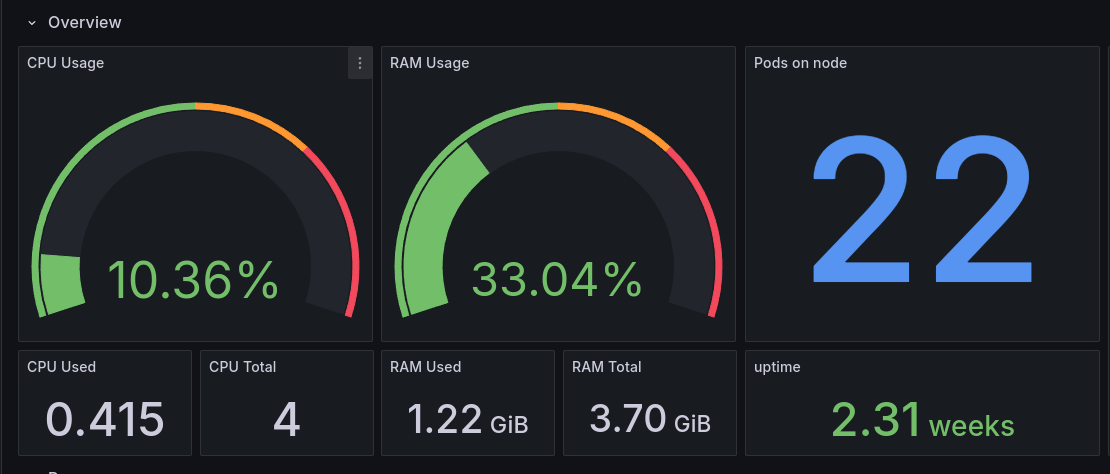
Worker 1
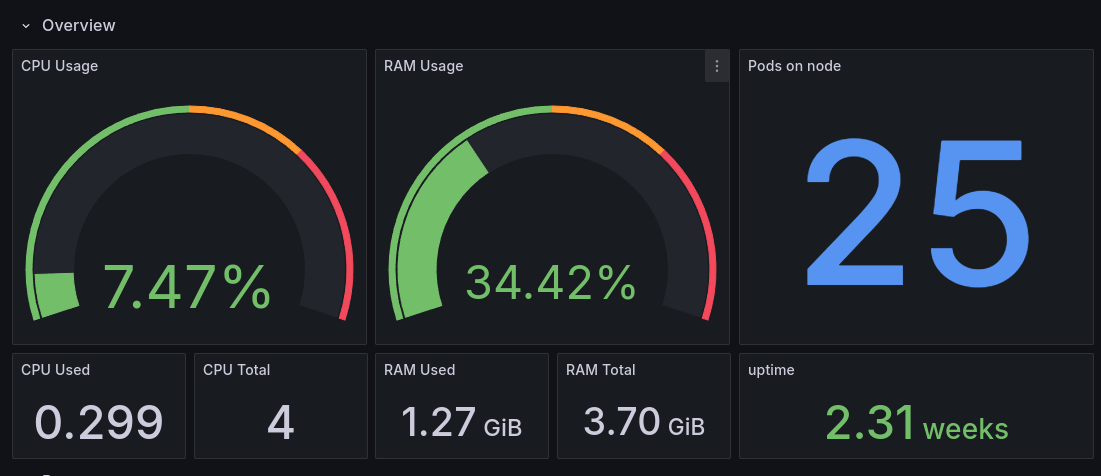
Storage
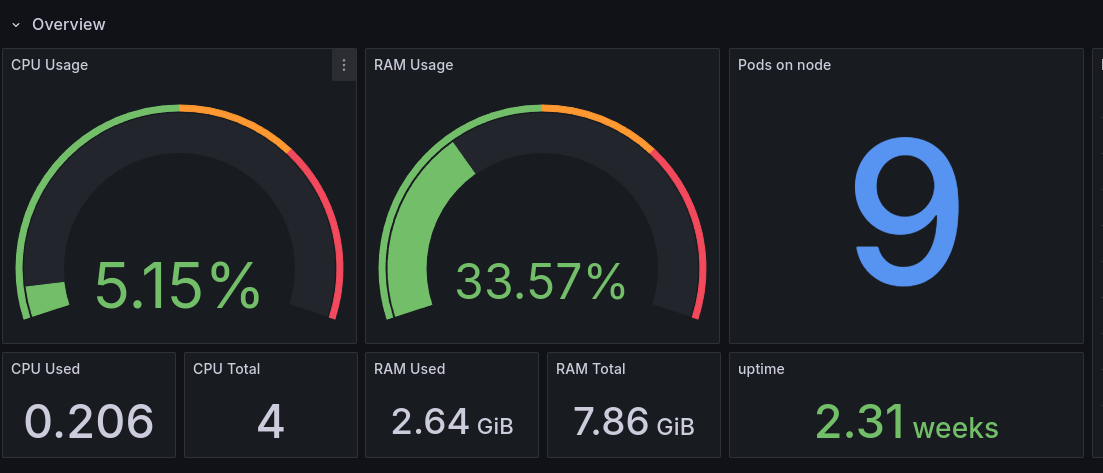
As you can see, I have a lot of resources even if my whole monitoring stack is installed, compared to last year when the Prometheus and Grafana Loki stack were installed.
Pretty happy how it turns out, and ready to install more stuff!