A guide on how to use Meilisearch as docsearch with HTMX
Tuesday 11 November 2025 · 53 mins read · Viewed 795 timesTable of contents 🔗
Introduction 🔗
Meilisearch is a search engine that allows to index content and search it with a simple query. Compared to existing solutions, Meilisearch tries to be simple and easy to use while being highly performant. You can check their comparison documentation.
The aim of this article is to present how to use Meilisearch as docsearch with Server-Side-Rendering. My blog has recently replaced the simple "Search via Duckduckgo" with a self-hosted Meilisearch instance.
Before getting into the details, I wanted to warn that my experience with other solution like Elasticsearch, Algolia and Typesense is very limited, so I won't be able to give you a proper state of the art. However, here's the problematic that I encountered with this very blog.
A need for a search engine 🔗
Like any blog, every article must be referenced one way or another. A good solution is to simply put a search engine, which will index every article of the blog and make it discoverable. As said in the introduction, my first solution is to rely on DuckDuckGo to index and offer a way to search.
The issues with this solution is that DuckDuckGo and Google are the one choosing how to index the content of the blog. And, sometimes, some article is shown over a more relevant one, or worse: the article is not indexed. The solution to these issues is clear: I need to use a search engine that I own in SaaS or via Self-hosted.
Therefore, here's my requirements:
- Free and secure, with a low probability of "rug-pull".
- If self-hosted, it needs not only to be highly performant, but also to have low CPU and Memory usage, with no risk of memory leaks.
- Support for highlighting.
- Doesn't hinder the availability of the blog.
Which is why is studied these competitors, and found these conclusions:
- Bleve: Bleve is a go library that allows to index and search content. It's simple and easy to use, but sadly, it requires to make my application stateful. This was, however, a pretty interesting solution.
- Elasticsearch (and OpenSearch): Elasticsearch is distributed search engine, and it's the most popular one. Having used this one for logs, and since it is developed with Java, I know for a fact that this solution is heavy. This is why I didn't use it for my log storage, and use VictoriaLogs instead.
- Algolia: Algolia is a SaaS solution that allows to index and search content. It's also a very popular solution and offer a free tier for open source projects. Having an excellent experience with Algolia, I still chose to NOT use it for the sake of learning. If you are looking for a quick solution, I recommend Algolia.
- Typesense: Typesense is a direct alternative to Algolia, and offers clustering too, so it's also as competitive as Elasticsearch. In the technical sense, Typesense is the right solution for people who need a self-hosted solution, highly performant and highly available.
As you can see, Algolia and Typesense are the best fit for my needs... so why didn't used it? For one simple reason: Meilisearch is used in other self-hosted projects. This includes:
- Linkwarden: a solution to manage bookmarks, powered by AI.
- OpenList: a solution to manage files.
For the sake of avoiding having multiple self-hosted search engines, I decided to use Meilisearch.
Even though this is the definitive argument for why I chose Meilisearch. There is another reason why it is worth choosing Meilisearch over other solutions.
The index storage of Meilisearch is not stored on the RAM, but on disk. It uses memory mapping to work in the RAM. Meaning, Meilisearch is extremely lightweight when it isn't used, and is extremely performant when there is enough RAM to store the index.
How to use Meilisearch as docsearch 🔗
Enough chit-chat, let's get to the code.
Step 1: Indexing the website 🔗
Step 1.a: Before indexing the website, something you need to know 🔗
My blog is kind of special. While it is served over a Go application, it is actually serving static files and rendered HTML. A lot of "computation" like indexing is done at compile-time, and if not, it is done at initialization time, making my website extremely low in RAM and CPU usage.
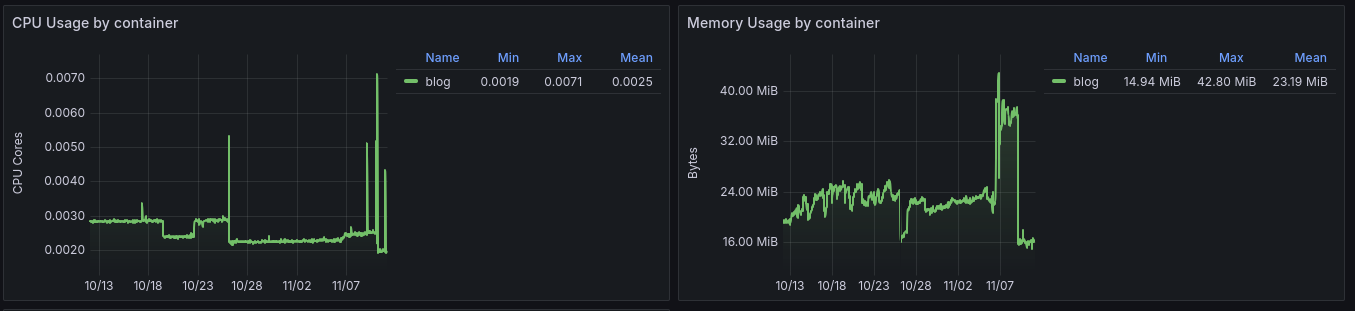
CPU and Memory usage over 30 days
Here's compared to a SvelteKit application:
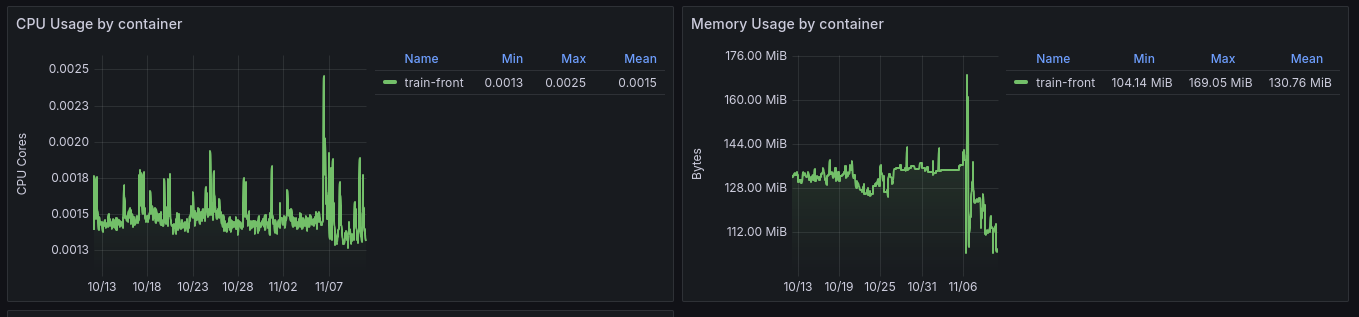
SvelteKit CPU and Memory usage over 30 days
I would like to point out that the SvelteKit application is a simple website that displays French train stations. SvelteKit is a full-stack solution, but most of the logic is delegated to another Go application.
Since my blog is already indexed at the time of compilation, all I have to do is fill in the missing data. But don't worry too much, this article covers the whole implementation, and running it at compile-time or at runtime is the same.
To implement Docsearch, the aim is to have an array of Record that will be sent to Meilisearch:
1package record
2
3type Records []Record // We want this
4
5type Record struct {
6 ObjectID string `json:"objectID"`
7 HierarchyLvl0 string `json:"hierarchy_lvl0,omitempty"`
8 HierarchyLvl1 string `json:"hierarchy_lvl1,omitempty"`
9 HierarchyLvl2 string `json:"hierarchy_lvl2,omitempty"`
10 HierarchyLvl3 string `json:"hierarchy_lvl3,omitempty"`
11 HierarchyLvl4 string `json:"hierarchy_lvl4,omitempty"`
12 HierarchyLvl5 string `json:"hierarchy_lvl5,omitempty"`
13 HierarchyLvl6 string `json:"hierarchy_lvl6,omitempty"`
14 Content string `json:"content"`
15 URL string `json:"url"`
16 Anchor string `json:"anchor"`
17}
Each Record is a document in Meilisearch, with objectID being the primary key. To do this, we need to:
- Search every articles in the blog. Usually, Algolia and Typesense will give you a scraper to automatically find the articles.
- Parse the articles and extract the data.
- Index the data in Meilisearch.
Step 1.b: Search the articles in the blog 🔗
First, I list every articles of my blog by using simple os.ReadDir and os.Open:
1package index
2
3// ... imports
4
5func BuildIndex() (index Index, err error) {
6 // First, read the directory that is supposed to hold articles
7 //
8 // In my blog, articles are stored in "pages" with the following pattern:
9 //
10 // pages/YYYY-MM-DD-title/page.md
11 entries, err := os.ReadDir("pages")
12 if err != nil {
13 return index, err
14 }
15
16 // Sort the files in reverse order
17 sort.SliceStable(entries, func(i, j int) bool {
18 return entries[i].Name() > entries[j].Name()
19 })
20
21 index = newIndex() // TODO: To be implemented
22 for _, entry := range entries {
23 // We are looking for directories (YYYY-MM-DD-title/)
24 if !entry.IsDir() {
25 continue
26 }
27 // It's a directory, so we expect a page.md.
28 f, err := os.Open(filepath.Join("pages", entry.Name(), "page.md"))
29 if err != nil {
30 continue
31 }
32 finfo, err := f.Stat()
33 if err != nil {
34 log.Err(err).
35 Str("entry", entry.Name()).
36 Msg("ignored for index, failed to stat page.md")
37 continue
38 }
39 if finfo.IsDir() {
40 continue
41 }
42 b, err := io.ReadAll(f)
43 if err != nil {
44 // NB: I prefer to crash here since this is compile-time.
45 // You would properly handle this error.
46 log.Fatal().Err(err).Msg("read file failure")
47 }
48
49 // TODO: Parse document
50 }
51
52 return index, nil
53}
Step 1.c: Parse the articles 🔗
My pages are in Markdown format, so I'll use a Markdown parser. If your pages are in HTML, you would use an HTML parser.
More precisely, my blog use Goldmark to build HTML pages from markdown pages at compile-time. By using Goldmark instead of an HTML parser, I'll be able to see more easily the information that I need.
For example, my articles are written like this:
1---
2title: Modal dialog with Hyperscript and PicoCSS
3description: Small article about a deadly combination.
4tags: [dialog, modal, hyperscript, picocss, css, js, html, htmx]
5---
6
7## Table of contents
8
9...
Metadata can be stored in these YAML metadata blocks. By using a Goldmark parser, I am able to extract these informations.
Looking at the algorithm at step 1.b, it's preferable to use a tree-like structure than a flattened array:
1func newIndex() Index {
2 return Index{
3 Pages: make([]Page, 0, 1), // We know there will be at least 1 page.
4 }
5}
6
7type Index struct {
8 Pages []Page
9}
10
11type Page struct {
12 EntryName string // 2025-11-10-dialog-hyperscript-picocss
13 PublishedDate time.Time // 2025-11-10
14 Title string // Modal dialog with Hyperscript and PicoCSS
15 Href string // /blog/2025-11-10-dialog-hyperscript-picocss
16 // We are not using Description for indexing. You can add it if you want it to be searchable.
17 Description string
18 Hierarchy []*Header
19}
20
21type Header struct {
22 Level int
23 Text string
24 Anchor string
25 // We are also not using Content for indexing. But if you plan to use Meilisearch for docsearch,
26 // I would heavily recommend using it.
27 // This, however, drastically increase the difficulty of indexing, as you'll need to properly
28 // Extract the content of each section, and clean it.
29 Content string
30 Children []*Header
31}
Let's start with the "smallest" object, the Header. To find headers in markdown, you'll need to walk the document to find ast.Heading elements. This would look like this:
1// headerInfo is used to track position of headers so we can extract their content
2type headerInfo struct {
3 header *Header
4 node *ast.Heading
5 start int // Start position after this heading
6 end int // End position (start of next heading or EOF)
7}
8
9// extractHeaders walks the AST and extracts all headers with their content
10func extractHeaders(n ast.Node, source []byte) []*Header {
11 var headers []*Header
12 var headingInfos []headerInfo
13
14 // First pass: collect all headings and their positions
15 ast.Walk(n, func(node ast.Node, entering bool) (ast.WalkStatus, error) {
16 if !entering {
17 return ast.WalkContinue, nil
18 }
19 if heading, ok := node.(*ast.Heading); ok {
20 text := extractHeaderText(heading, source)
21
22 // Extract anchor (id attribute), this requires `parser.WithAutoHeadingID()`
23 t, _ := heading.AttributeString("id")
24 anchor := string(t.([]byte))
25
26 header := &Header{
27 Level: heading.Level,
28 Text: text,
29 Anchor: anchor,
30 Content: "",
31 Children: []*Header{},
32 }
33
34 headers = append(headers, header)
35
36 // Track position info - content starts after this heading ends
37 // Use the stop position of the last line of the heading
38 lastLine := heading.Lines().At(heading.Lines().Len() - 1)
39 headingInfos = append(headingInfos, headerInfo{
40 header: header,
41 node: heading,
42 start: lastLine.Stop,
43 })
44 }
45 return ast.WalkContinue, nil
46 })
47
48 // (Optional) If you need content parsing, this is the implementation.
49 // You'll need to implement `cleanContent`.
50 // // Second pass: determine content ranges and extract content
51 // for i := range headingInfos {
52 // // Find the end position (start of next heading at same or higher level)
53 // endPos := len(source)
54 // currentLevel := headingInfos[i].header.Level
55
56 // for j := i + 1; j < len(headingInfos); j++ {
57 // nextLevel := headingInfos[j].header.Level
58 // // Stop at next heading of same or higher level (lower level number = higher in hierarchy)
59 // if nextLevel <= currentLevel {
60 // // Get the start of the next heading's first line
61 // endPos = headingInfos[j].node.Lines().At(0).Start
62 // break
63 // }
64 // }
65
66 // headingInfos[i].end = endPos
67
68 // // Extract content between start and end positions
69 // contentBytes := source[headingInfos[i].start:headingInfos[i].end]
70 // headingInfos[i].header.Content = cleanContent(contentBytes)
71 // }
72
73 return headers
74}
75
76// extractHeaderText extracts the text content from a heading node
77func extractHeaderText(heading *ast.Heading, source []byte) string {
78 var buf bytes.Buffer
79 for child := heading.FirstChild(); child != nil; child = child.NextSibling() {
80 if textNode, ok := child.(*ast.Text); ok {
81 buf.Write(textNode.Segment.Value(source))
82 }
83 }
84 return buf.String()
85}
86
87// buildHierarchy converts a flat list of headers into a hierarchical structure
88func buildHierarchy(headers []*Header) []*Header {
89 if len(headers) == 0 {
90 return []*Header{}
91 }
92
93 var root []*Header
94 var stack []*Header
95
96 for _, header := range headers {
97 // Pop stack until we find a parent with lower level
98 for len(stack) > 0 && stack[len(stack)-1].Level >= header.Level {
99 stack = stack[:len(stack)-1]
100 }
101
102 if len(stack) == 0 {
103 // Top-level header
104 root = append(root, header)
105 } else {
106 // Add as child to the parent
107 parent := stack[len(stack)-1]
108 parent.Children = append(parent.Children, header)
109 }
110
111 // Push current header onto stack
112 stack = append(stack, header)
113 }
114
115 return root
116}
The usage is the following:
1func BuildIndex() (index Index, err error) {
2 // Initiliaze goldmark
3 markdown := goldmark.New(
4 // Required for proper anchor IDs. If you are NOT using Goldmark to render Markdown to HTML,
5 // you'll need to implement your own solution by copying the implmentation of the Markdown-to-HTML renderer.
6 goldmark.WithParserOptions(parser.WithAutoHeadingID()),
7 goldmark.WithExtensions(
8 meta.New(
9 meta.WithStoresInDocument(),
10 ),
11 ),
12 )
13
14 // ...
15
16 for _, entry := range entries {
17 // ...
18
19 b, err := io.ReadAll(f)
20 if err != nil {
21 // NB: I prefer to crash here since this is compile-time.
22 // You would properly handle this error.
23 log.Fatal().Err(err).Msg("read file failure")
24 }
25
26 document := markdown.Parser().Parse(text.NewReader(b))
27
28 headers := extractHeaders(document, b)
29 hierarchy := buildHierarchy(headers)
Then to fetch metadata, thanks to goldmark-meta, we can do the following:
1 // ...
2 metaData := document.OwnerDocument().Meta()
3 date, err := extractDate(entry.Name())
4 if err != nil {
5 log.Fatal().Err(err).Msg("failed to read date")
6 }
7 index.Pages = append(index.Pages, Page{
8 EntryName: entry.Name(),
9 PublishedDate: date,
10 Title: fmt.Sprintf("%v", metaData["title"]),
11 Description: fmt.Sprintf("%v", metaData["description"]),
12 Href: path.Join(
13 "/blog",
14 entry.Name(),
15 ), // NOTE: You'll need to change this to match your blog structure
16 Hierarchy: hierarchy,
17 })
18 }// for _, entry := range entries
19
20 return index, nil
21} // func BuildIndex()
22
23// extractDate extracts the date from the filename
24func extractDate(filename string) (time.Time, error) {
25 // Split the filename by "-"
26 parts := strings.Split(filename, "-")
27
28 // Check if there are enough parts in the filename
29 if len(parts) < 3 {
30 return time.Time{}, fmt.Errorf("invalid filename format: %s", filename)
31 }
32
33 // Extract the date part (YYYY-MM-DD)
34 dateStr := strings.Join(parts[:3], "-")
35
36 // Parse the date string into a time.Time object
37 date, err := time.Parse("2006-01-02", dateStr)
38 if err != nil {
39 return time.Time{}, err
40 }
41
42 return date, nil
43}
We can run some tests:
1package main
2
3import (
4 "example/index"
5 "fmt"
6)
7
8func main() {
9 index, err := index.BuildIndex()
10 if err != nil {
11 panic(err)
12 }
13 fmt.Printf("%v\n", index)
14}
15
which works!
Step 1.d: Send documents to Meilisearch 🔗
We have the Index structure, and we want to convert it into []Record. I'll instead convert to iter.Seq[Record] in case I need to prepare batches.
The lvl0 will be groups, so I'll prefer to group by date. Usually, for a docsearch, you'll want set the hierarchy like this:
- Level 0: Documentation path
- Level 1: Documentation title (Header level 1/h1)
- Level 2: Header level 2 (h2)
- ...
But, in reality, you are free to choose any method for grouping records. The levels correspond to how you will display the hierarchy. I chose to proceed as follows:
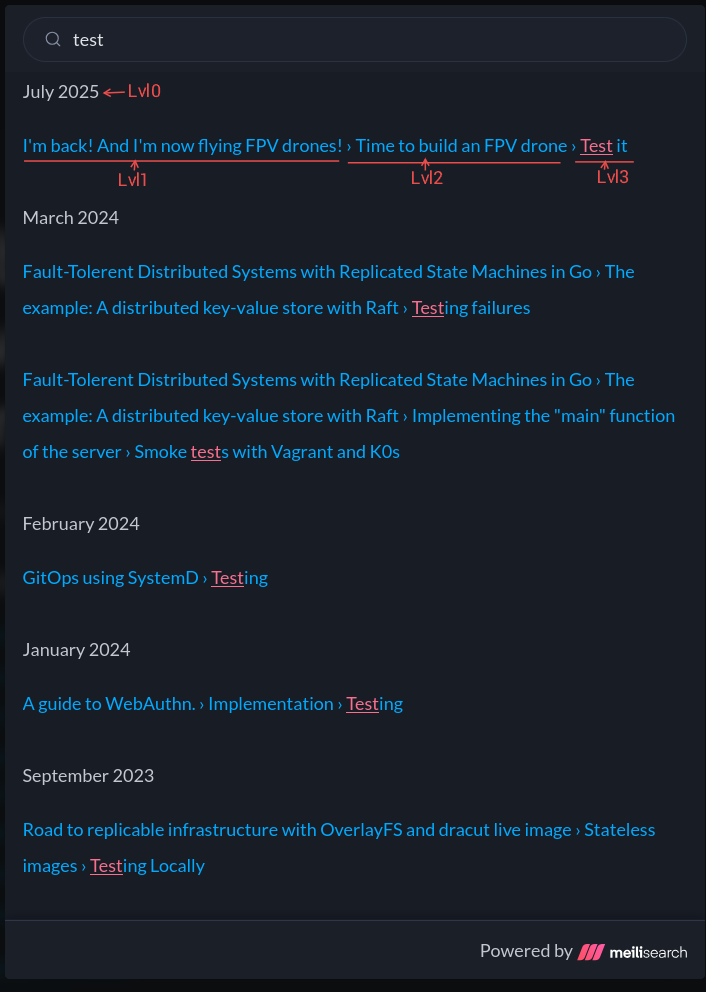
- Level 0: Article date
- Level 1: Documentation title (Header level 1/h1)
- Level 2: Header level 2 (h2)
- ...
Which means, to convert the Index into a []Record, my implementation is the following:
1// FromIndex converts an Index to a slice of search Records
2func FromIndex(index index.Index) iter.Seq[Record] {
3
4 return func(yield func(Record) bool) {
5 for _, page := range index.Pages {
6 // Base hierarchy levels
7 lvl0 := page.PublishedDate.Format("January 2006")
8 lvl1 := page.Title
9
10 // 1. **Directly yield the Level 2 Record**
11 lvl2Record := Record{
12 ObjectID: page.EntryName,
13 HierarchyLvl0: lvl0,
14 HierarchyLvl1: lvl1,
15 HierarchyLvl2: "",
16 HierarchyLvl3: "",
17 HierarchyLvl4: "",
18 HierarchyLvl5: "",
19 HierarchyLvl6: "",
20 Content: "",
21 URL: page.Href,
22 Anchor: "",
23 }
24
25 if !yield(lvl2Record) {
26 return
27 }
28
29 // 2. **Pass the yield function to processHeader**
30 for _, header := range page.Hierarchy {
31 // Check if we need to stop based on the return value of processHeader
32 if !processHeader(
33 header,
34 page,
35 lvl0,
36 lvl1,
37 "",
38 "",
39 "",
40 "",
41 "",
42 yield, // Pass the yield function directly
43 ) {
44 return // Stop the entire sequence
45 }
46 }
47 }
48 }
49}
50
51// processHeader recursively processes headers and creates records, yielding them directly.
52func processHeader(
53 h *index.Header,
54 page index.Page, // Renamed 'index' to 'idx' to avoid shadowing the package name
55 lvl0, lvl1, lvl2, lvl3, lvl4, lvl5, lvl6 string,
56 yield func(Record) bool,
57) bool { // Now returns a boolean to indicate continuance (true = continue, false = stop)
58
59 switch h.Level {
60 case 1:
61 // Skip H1 headers (assuming the top-level article title is lvl2)
62 log.Warn().Msg("Skipping H1 header: conflicts with article title")
63 return true // Continue processing other headers
64 case 2:
65 lvl2 = h.Text
66 case 3:
67 lvl3 = h.Text
68 case 4:
69 lvl4 = h.Text
70 case 5:
71 lvl5 = h.Text
72 case 6:
73 lvl6 = h.Text
74 default:
75 // Ignore headers beyond H5
76 return true // Continue processing other headers
77 }
78
79 // 1. Create record for this header
80 record := Record{
81 ObjectID: page.EntryName + "-" + h.Anchor,
82 HierarchyLvl0: lvl0,
83 HierarchyLvl1: lvl1,
84 HierarchyLvl2: lvl2,
85 HierarchyLvl3: lvl3,
86 HierarchyLvl4: lvl4,
87 HierarchyLvl5: lvl5,
88 HierarchyLvl6: lvl6,
89 Content: h.Content,
90 URL: page.Href + "#" + h.Anchor,
91 Anchor: h.Anchor,
92 }
93
94 // 2. **Directly yield the record**
95 if !yield(record) {
96 return false // Stop if the consumer doesn't want more records
97 }
98
99 // 3. Process children, passing down the **new** hierarchy levels
100 for _, child := range h.Children {
101 // If a child call returns false, stop everything and propagate the 'false'
102 if !processHeader(
103 child,
104 page,
105 lvl0,
106 lvl1,
107 lvl2,
108 lvl3,
109 lvl4,
110 lvl5,
111 lvl6,
112 yield,
113 ) {
114 return false
115 }
116 }
117
118 return true // Continue to the next sibling header
119}
After we've got our records, we can send them to Meilisearch. You can use meilisearch-go to quickly have a client. Otherwise, you can implement your own client using HTTP.
For the sake of the article, we'll use the library, but I would recommend using your own implementation to avoid adding dependencies to your project.
1package main
2
3import (
4 "example/index"
5 "example/record"
6 "fmt"
7 "slices"
8 "time"
9
10 "github.com/meilisearch/meilisearch-go"
11)
12
13func main() {
14 index, err := index.BuildIndex()
15 if err != nil {
16 panic(err)
17 }
18 records := slices.Collect(record.FromIndex(index)) // Collect and send everything all at once
19 fmt.Printf("%v\n", records)
20
21 client := meilisearch.New(
22 "http://localhost:7700", // TODO: Replace this
23 meilisearch.WithAPIKey("YK50yAklJnG13vz3TmyX1XKhJSkMo87p"), // TODO: Replace this
24 ).Index("blog") // TODO: Replace this
25
26 primaryKey := "objectID"
27 tinfo, err := client.AddDocuments(records, &primaryKey)
28 if err != nil {
29 panic(err)
30 }
31 fmt.Printf("%v\n", tinfo)
32 _, err = client.WaitForTask(tinfo.TaskUID, time.Second)
33 if err != nil {
34 panic(err)
35 }
36}
Congratulations! You've just indexed your website using Meilisearch! But this is not finished yet, we need to set a search bar.
Step 2: Setting up the search engine 🔗
Step 2.a: Serving the index 🔗
We'll use HTMX to do the server side rendering. I'll be also be using Hyperscript and PicoCSS as helpers for the front-end (check the previous article). The index file will be directly served by the server as static file:
1import _ "embed"
2
3//go:embed index.html
4var html string
5
6func main() {
7 // ...
8
9 mux := http.NewServeMux()
10 mux.Handle("GET /", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
11 w.Write([]byte(html))
12 }))
13
14 http.ListenAndServe(":8080", mux)
15}
I won't be covering on how to render Markdown to HTML in this article as it is already covered in an old article.
The index HTML:
1<!DOCTYPE html>
2<html>
3 <head>
4 <meta charset="utf-8" />
5 <meta http-equiv="X-UA-Compatible" content="IE=edge" />
6 <title>Page Title</title>
7 <meta name="viewport" content="width=device-width, initial-scale=1" />
8 <script
9 hx-preserve="true"
10 src="https://unpkg.com/htmx.org@2.0.6"
11 integrity="sha384-Akqfrbj/HpNVo8k11SXBb6TlBWmXXlYQrCSqEWmyKJe+hDm3Z/B2WVG4smwBkRVm"
12 crossorigin="anonymous"
13 ></script>
14 <script
15 hx-preserve="true"
16 src="https://unpkg.com/hyperscript.org@0.9.14"
17 integrity="sha384-NzchC8z9HmP/Ed8cheGl9XuSrFSkDNHPiDl+ujbHE0F0I7tWC4rUnwPXP+7IvVZv"
18 crossorigin="anonymous"
19 ></script>
20 <link
21 hx-preserve="true"
22 rel="stylesheet"
23 href="https://unpkg.com/@picocss/pico@2.1.1/css/pico.classless.min.css"
24 integrity="sha384-NZhm4G1I7BpEGdjDKnzEfy3d78xvy7ECKUwwnKTYi036z42IyF056PbHfpQLIYgL"
25 crossorigin="anonymous"
26 />
27 </head>
28 <body>
29 <!-- TODO -->
30 </body>
31</html>
Like my previous article, we'll be setting up a button and a modal to display the search bar, like Docsearch-style.
1<button _="on click call #search-dialog.showModal()">Search</button>
2
3<dialog id="search-dialog">
4 <article
5 _="on click[#search-dialog.open and event.target.matches('dialog')] from elsewhere call #search-dialog.close()"
6 >
7 <header style="margin-bottom: 0; height: 100px">
8 <input
9 type="search"
10 placeholder="Search..."
11 aria-label="Search"
12 style="margin: 0"
13 name="q"
14 hx-get="/search"
15 hx-trigger="keyup changed delay:100ms"
16 hx-target="#search-results"
17 />
18 </header>
19 <div
20 id="search-results"
21 style="
22 display: block;
23 scrollbar-width: thin;
24 overflow-y: auto;
25 overflow-x: hidden;
26 max-height: calc(100vh - var(--pico-spacing) * 2 - 60px - 100px);
27 "
28 ></div>
29 <footer
30 style="
31 height: 60px;
32 margin-top: 0;
33 box-shadow: rgba(73, 76, 106, 0.5) 0px 1px 0px 0px inset,
34 rgba(0, 0, 0, 0.2) 0px -4px 8px 0px;
35 "
36 >
37 <div>
38 Powered by <a href="https://www.meilisearch.com/">Meilisearch</a>
39 </div>
40 </footer>
41 </article>
42</dialog>
Which makes this:
If you haven't read the last article, here's a summary. By using Hyperscript, I'm able to write short code in the front-end, without javascript, to interact with the DOM. Here's the portion of code using Hyperscript:
_="on click call #search-dialog.showModal()": I'm calling theshowModalmethod on thesearch-dialogelement.on click[#search-dialog-demo.open and event.target.matches('dialog')] from elsewhere call #search-dialog-demo.close(): If the user click outside the dialog, I'm calling theclosemethod on thesearch-dialogelement.
That's it! For HTMX, the interesting component is:
1<input
2 type="search"
3 placeholder="Search"
4 aria-label="Search"
5 style="margin: 0"
6 name="q"
7 hx-get="/search"
8 hx-trigger="keyup changed delay:100ms"
9 hx-target="#search-results"
10/>
which indicates to send a GET /search?q=<value> request to the server when typing in the input. The response will be rendered in the #search-results element by swapping the innerHTML of the element.
Now that we've got our search widget ready, it is now time to focus on the server-side.
Step 2.b: Serving the search results 🔗
Let's focus on the /search handler first:
1func Handler(meili meilisearch.SearchReader) http.HandlerFunc {
2 return func(w http.ResponseWriter, r *http.Request) {
3 ctx := r.Context()
4 q := r.URL.Query().Get("q")
5
6 if q == "" {
7 return
8 }
9
10 // TODO: send the request to meilisearch and serve the result
11
12 w.Header().Set("Content-Type", "text/html")
13 }
14}
1 // ...
2 mux := http.NewServeMux()
3 mux.Handle("GET /", http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
4 w.Write([]byte(html))
5 }))
6 mux.Handle("GET /search", search.Handler(client)) // Added
7
8 http.ListenAndServe(":8080", mux)
9}
We'll send a search request to Meilisearch with highlighting. Our result will be looking more like this:
1// ...
2type RecordWithFormat struct {
3 record.Record `json:",inline"`
4 Formatted record.Record `json:"_formatted"`
5}
6// ...
And we'll send the request like this:
1func Handler(meili meilisearch.SearchReader) http.HandlerFunc {
2 return func(w http.ResponseWriter, r *http.Request) {
3 // ...
4
5 res, err := meili.SearchWithContext(ctx, q, &meilisearch.SearchRequest{
6 AttributesToHighlight: []string{"*"},
7 AttributesToCrop: []string{"content"},
8 CropLength: 30,
9 })
10 if err != nil {
11 log.Err(err).Msg("Error searching")
12 http.Error(w, err.Error(), http.StatusInternalServerError)
13 return
14 }
15 var records []RecordWithFormat
16 if err := res.Hits.DecodeInto(&records); err != nil {
17 log.Err(err).Msg("Error decoding search results")
18 http.Error(w, err.Error(), http.StatusInternalServerError)
19 return
20 }
21
22 // TODO: render the records in HTML
23
24 // ...
25
26 w.Header().Set("Content-Type", "text/html")
27 }
28}
At this point, you're free to render the results in any way you want. I'll be grouping by lvl0:
1func recordsGroupByLvl0(
2 records []RecordWithFormat,
3) (m map[string][]RecordWithFormat, keys []string) {
4 m = make(map[string][]RecordWithFormat)
5
6 for _, r := range records {
7 if _, ok := m[r.HierarchyLvl0]; !ok {
8 keys = append(keys, r.HierarchyLvl0)
9 m[r.HierarchyLvl0] = make([]RecordWithFormat, 0, 1)
10 }
11 m[r.HierarchyLvl0] = append(m[r.HierarchyLvl0], r)
12 }
13 return
14}
I will use html/template, and since I use highlighting, I need to avoid escaping the HTML:
1import _ "embed"
2
3//go:embed search.tpl
4var searchTemplate string
5
6func funcsMap() template.FuncMap {
7 m := sprig.HtmlFuncMap()
8 m["noescape"] = func(s string) template.HTML { return template.HTML(s) }
9 return m
10}
11
12func Handler(meili meilisearch.SearchReader) http.HandlerFunc {
13 return func(w http.ResponseWriter, r *http.Request) {
14 // ...
15
16 groupedRecords, lvl0s := recordsGroupByLvl0(records)
17
18 if err := template.Must(template.New("base").
19 Funcs(funcsMap()).
20 Parse(searchTemplate)).
21 Execute(w, map[string]any{
22 "Lvl0s": lvl0s,
23 "GroupedRecords": groupedRecords,
24 }); err != nil {
25 log.Err(err).Msg("template error")
26 http.Error(w, err.Error(), http.StatusInternalServerError)
27 return
28 }
29
30 w.Header().Set("Content-Type", "text/html")
31 }
32}
With search.tpl being:
At this point, we have a fully functional search widget.
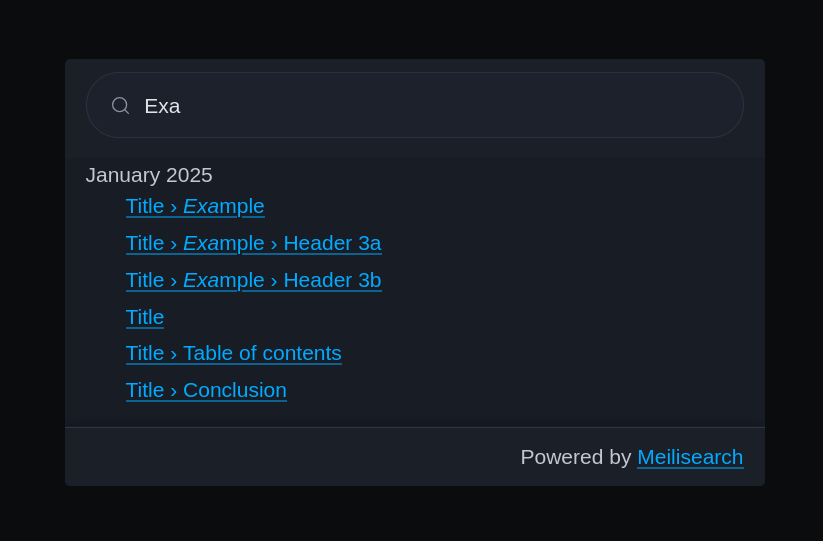
Conclusion 🔗
This is a very simple example of how to use Meilisearch as a docsearch, with HTMX.
I am quite happy on how it is implemented on my blog right now, and I hope it can be useful for you too.
Source code is available on GitHub.